De siste 10-20 årene har fysiske lagringsformater gradvis blitt erstattet av filer i radio- og TV-produksjon. Dette gjør at noe har blitt enklere – men noe annet – la oss kalle det «logistikken» – har blitt vesentlig vanskeligere. Innholdet vårt er ikke lenger på et bånd som ligger pent på pulten til den som jobber med det – eller står i hyllene i et arkiv. Det er i en hurtig voksende mengde filer som helst bør finnes igjen tre måneder senere – og tre år senere. For ikke å snakke om å holde rede på de ulike versjonene: Netflix har f.eks. 33.000 ulike versjoner av Disney-filmen Frozen for alle de ulike markedene de betjener.
Hvor er filene mine?
BBC startet for ca. 20 år siden et stort logistikk-prosjekt kalt the Jupiter project. De prøvde å ta tak i følgende utfordring: Når et stadig voksende mediehus lagrer tusenvis av filer hver eneste dag, hvordan skal de finne igjen datafilene (programmer, nyhetsklipp, musikk, stillbilder) etterhvert som lagrene vokser til millioner av filer?
«It’s no point having fabulous content – if viewers can’t find it.»
BBC Jupiter project
NRKs fjell av filer

NRKs tre spillere http://tv.nrk.no, http://radio.nrk.no og http://tv.nrksuper.no inneholder allerede nærmere 1 million datafiler – over 190.000 radio- og TV-programmer. Og de vokser med ca. 1.000 programmer pr uke.
Streaming i ulike kvaliteter
Hvert program består av 5 video-datafiler (MPEG4, adaptiv streaming) og en manifest-fil som forteller nett-distributøren Akamai «hva som ligger i pakken». Dataraten på filene varierer fra ca. 0,3 Mbps til 2,4 Mbps (TV). Når programmet spilles av, velges kvalitet ut i fra båndbredden som er tilgjengelig for deg som bruker. Det vil variere ut i fra hvilken dings du bruker – og hva slags nett som til enhver tid er tilgjengelig.
Råstoff
Men før dette når fram til ferdig program, har NRK allerede holdt styr på et utall råstoff-filer som er lastet inn fra kameraene våre. Et enkelt TV-program kan ta utgangspunkt i fra noen hundre til mange titusener råstoff-filer. Opptaksformatet hos NRK har akkurat byttet til Sonys nye MPEG4-format (X.AVC) og holder 100 Mbps bitrate. Dramaproduksjon bruker enda høyere oppløsning – 4k eller bedre. Råstoff-filer beholdes som regel lokalt på de enkelte redigeringsenheter – eller i store råstofflagre (XSAN-systemer). NRK lagrer nå mer enn 1,3 PB (peta-Byte = ca. 1 million GigaByte) av råstoff-filer og dette øker med voksende produksjon og bedre formater.
Ferdig innhold
Når programmene er ferdige, lagres de på store sentrale medieservere (Harmonic MediaGrid) i produksjonskvalitet (HD – 1080i50 – i 50 eller 100 Mbps). Fra disse filene lages alle kvalitetene for avspilling mot publikum. Dette gjøres i egne «transkodingssystemer» (som regel av typen Telestream Vantage). Og her kjøres det også egne kvalitetssikringsprosesser for å sikre både egenproduserte programmer og innkjøpte produksjoner. Fra sentrale medieservere lages også påsynsfiler for avspilling på alle PCer internt i NRK. Dette er nødvendig både for søk og gjenbruk av filer – og for å lage ekstraelementene i programmene – teksting i mange forskjellige formater, grafikk og super-tekster – f.eks. grafikk som forteller hvem du ser i bildet – («Erna Solberg – statsminister»). Medieserverne til NRK kan inneholde over 30.000 timer video.
Arkivet
Selv dette blir lite når vi ser på alt som er lagret gjennom historien. NRKs lager av video ligger nå hovedsakelig på en stor tape-robot «et eller annet sted i NRK-kjelleren» ( Oracle StorageTek tape-robot). Denne inneholder over 6600 datataper med over 155.000 timer med video. Det meste av det gamle båndarkivet er nå konvertert til digital form og er tilgjengelig her – som datafiler på en tapekassett. Disse tar noen få minutter å starte innlasting av over på en medieserver – men som påsynsfil kan de alltid spilles av umiddelbart. Det finnes også et bufferlager som inneholder de siste månedenes produksjon, slik at ikke alt fra arkivet må hentes fra tape-roboten.

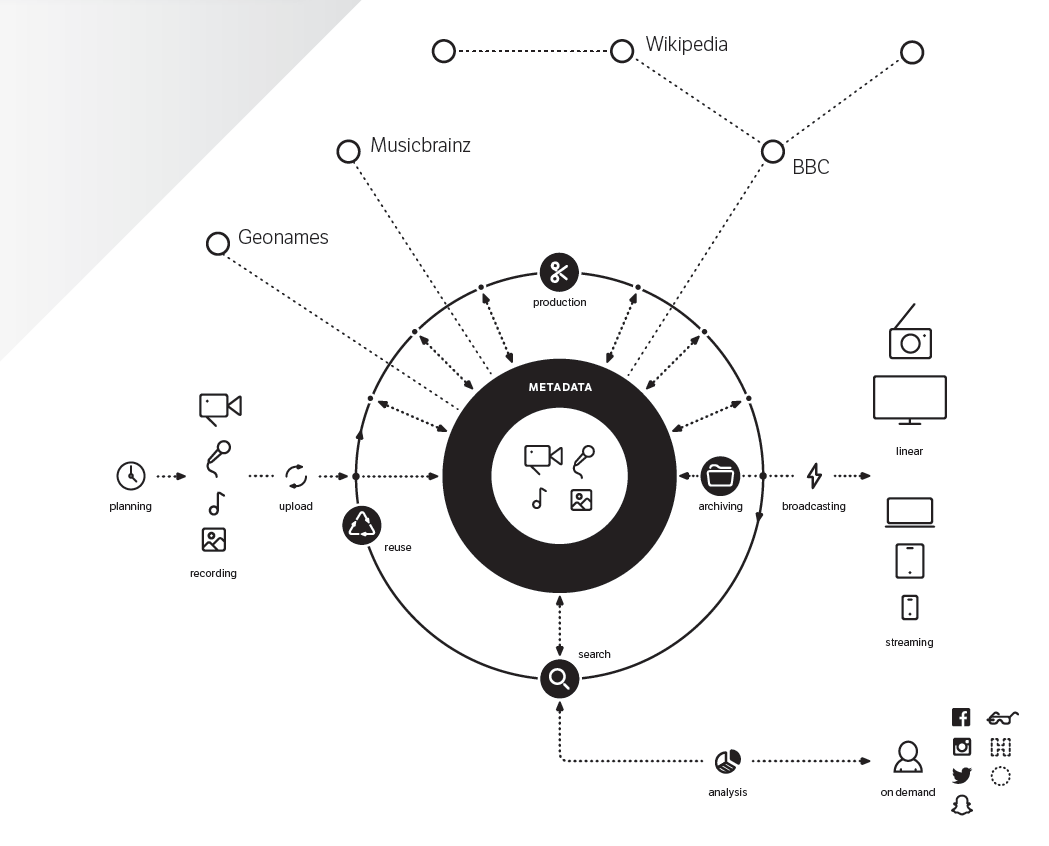
Metadata
Men det viktigste er at vi alltid har metadata – beskrivelse av programmene – tilgjengelig for søk og gjenfinning. Det var her problemet begynte for BBC – hvordan i alle verden skal vi kunne finne igjen programmene våre? Hvordan leter du etter gamle innslag blant 107.000 Dagsnytt-filer eller 20.000 Dagsrevyer?
NRK-spillerne = metadata-revolusjon 1
Da NRK bygget tv.nrk.no og de andre spillerne, visste vi at brukervennligheten sto og falt på gode metadata. Og metadata for historiske program var gjemt i en god del ulike – svært ulike – systemer:
- PRF (Programplanlegging og Rapportering i Fjernsyn) fra firmaet MediaGenix inneholdt planleggings- og rettighetsdata for alle programmene (tittel, medvirkende, rettigheter, sendedato med MYE mer)
- PI (Oracle database) var databasen alt ble hentet ut i (den ble oppdatert en gang i døgnet)
- Granitt (Oracle database med ny Gluon datamodell) – ble etablert for å inneholde alle metadata for programmer som ble publisert mot publikum (NRK-spillerne). Gluon var formatet som NRK utviklet FØR det standardiserte formatet EBUcore fra den Europeiske kringkastingsunionen EBU. NRK har vært sterkt medvirkende til etableringen av dette.
- Programbanken – NRKs produksjonsplattform for video – inneholder alle metadata for videoproduksjon.
- Digas (NRKs radioproduksjons-system) – Inneholdt metadata for alle radioprogrammer UNDER produksjon.
- Digitalt radioarkiv (Nasjonalbiblioteket) – samarbeidsprosjekt mellom NRK og Nasjonalbiblioteket i Mo i Rana, inneholder alle historiske metadata og lydfiler for det av NRKs radioproduksjon som har blitt tatt vare på. (Om lag 85% av NRKs radioproduksjon før 1990 er dessverre ikke tatt vare på. Lagring av innhold var en høy kostnad og svært plasskrevende for NRKs i tidlige tider – og derfor ble bånd ofte resirkulert.)
- SIFT (norskutviklede Søking I Fri Tekst) – NRKs metadata-databaser for radio og TV (og en av de få bærere for metadata fram til ca. 1997).
- MediaDB (NRK-utviklet database «vasket» ut fra SIFT for TV-delen av SIFT fram til ca. 1997)
- Nyhetsdata-systemer – BaSYS og ENPS (ikke veldig godt integrert med metadatalagring før etter 2010.) En del av dataene finnes i SIFT, men mangler referanser og struktur for god gjenfinning.
Når dette skulle settes sammen i den nye databasen Granitt (webpubliseringsdatabasen), krevdes omfattende programvareutvikling for at dette skulle gå bra. Feil data ville gjøre det vanskelig for publikum å finne fram i NRK-spillerne – og vanskelig for oss å finne programmer (og biter av disse) til ny TV-produksjon. Utviklingen av NRK-spillerne støtte på en rekke utfordringer i forhold til å kunne gjøre metadataene gode nok (basert på historiske data i samlingene), og på å kunne gjøre søk raskt nok til å være brukervennlig. I starten av utviklingen kunne søk ta over et halvt minutt fordi spørringene ble gjort fra én database mot neste – oppslag i 3 millioner linjer tar tid. Og hvor mange ville ventet 30 sekunder – før de trykket EN GANG TIL…
Grunnstrukturen for NRKs metadata var lite forberedt på nye publiseringsformer. Etter mye arbeid ble utfordringene løst – og søketidene kom ned i det akseptable (under ett sekund eller bedre).
Shit In = Shit Out
Et tilsvarende arbeid ble gjort for å få alle redaksjoner i NRK til å levere gode metadata for alt nytt radio- og TV-materiale som skulle publiseres mot nett (dvs. de aller fleste). Et stort internt opplæringsprosjekt konsentrerte oppmerksomheten om følgende metadata (internt kalt 7MÅ – sju metadata-typer du MÅ levere for å publisere mot nett):
- Rubrikktekst (en kort beskrivelse av programinnhold)
- Rettigheter
- Indeksering (tittel på hvert enkelt innslag i programmet – og kanskje også medvirkende, stedsinformasjon mm.)
- Stillbilder (stillbilder koblet mot programmene – bl.a. for å illustrere disse i spillernes grensesnitt)
- Medvirkende
- Tags (emnemarkører som hjelper i gjenfinning)
- Sted (hvor)

7MÅ-kravene gjorde at vi fikk bedre metadata – og økte bevisstheten internt for at dette var viktig for publikum.
https://youtu.be/jJ5ZeMNn6lo
Tekstingen er en verdifull metadatakilde
Det ble også gjort en stor jobb for å sikre tilgang til teksting for alle programmer. Teksting er et undervurdert område og viste seg svært verdifullt som grunnlag for søk. En masse gode metadata er tilgjengelig i tekstefilene og gjør at søketreff blir mye bredere enn bare gjennom søk mot titler, programbeskrivelser og medvirkende.
Big data-problemet
NRKs arkiver inneholder nå over 25 millioner datafiler – video (råstoff, mastere og web-filer), lyd/radio, podcaster, stillbilder, teksting, grafikk, lydeffekter, og dokumenter (kontrakter mm). Vi lagrer over 250.000 nye programmer og minst 2 millioner nye datafiler hvert eneste år. I tilknytning til disse programmene har vi opptil 50 metadatafelter til hvert eneste program. Det gir potensielt over 1 milliard metadatafelter – selv om det her vil ligge mange dubletter ved at hver fil har versjoner og varianter.
Dette blir det en utfordring å holde styr på. Vi kaller det gjerne et «big data»-problem. Og dette er ikke bare ille for NRK – men for alle andre kringkastere også. En av utfordringene handler om varianter – og versjoner av programmene.
Big data hos Netflix
Varianter og versjoner er en av de virkelig store utfordringene i TV-produksjon. Når NRK lager en «master» av et program, går denne filen gjennom en rekke prosesser. Du er kanskje ikke helt fornøyd med første versjon (det er vi sjelden) – så lages en versjon 2. Denne går til lydbearbeiding – og du får versjon 3. Denne går igjen til fargekorreksjon – og du har skapt versjon 4. Så får producer en god idé til en liten retting – og du har fått versjon 5. Det kommer et lite juridisk problem med en rettighetshaver, så et kunstverk som blir vist må fjernes – ny liten redigering og du har fått versjon 6. Og slik kan det fortsette…

33.000 versjoner av Frozen
Netflix er en av verdens største distributører for film og serier via nett. En av filmene de har distribuert, er Disneys animasjonsfilm Frozen. Slik ser versjonering ut hos Netflix: Master på 164 minutter mottatt fra Disney (versjon 1). Lag 110 forskjellige dubbede språkversjoner – og du har passert versjon 111. Beskjed fra kabel-TV om at de kun har plass til 150 minutters filer OTT – ny redigering av Frost til 150 minutters utgave – og du har fått 111 versjoner til (inkl. dubbede språkutgaver) – og passerer 222 versjoner. Med forskjellig teksting, dubbing, versjoner for spesielle «dingser», 4k-utgave, spesialversjoner med scener som må fjernes fra enkelte land (støtende scener eller annet) – kommer Netflix opp i [trommehvirvel] 33.000 versjoner av Frozen. Da blir det litt å holde styr på – hvis du ikke har noen triks i ermet.
Slik unngår Netflix å ha 5,3 petabyte med Frozen
Ett av tricksene til Netflix heter IMF – Interoperable Master Format. Det gjør at de ikke må lagre så mye – men kan se alle varianter under ett. Rammeverket reduserer lagringsbehovet og versjoner består ikke lenger av alle komponenter – bare referanse til «master»-delene og bruken av disse. Det gjør at lagring reduseres dramatisk. De sier selv at hvis de IKKE hadde gjort noe, hadde de endt opp med 5,3 PB i lagring – KUN for Frozen.
Våre tricks
NRK har ikke Netflix’ utfordring med havet av versjoner for ulike markeder, men vi har til gjengjeld betydelig mer innhold å holde rede på enn Netflix: De har et tusentalls titler, NRK har krysset 50.000 On Demand-tilgjengelige program, og har betydelig mer i kjelleren – inkludert råstoff.
De triksene vi har i ermet for å håndtere vårt innholdsberg, handler om bedre struktur, metadata-arbeidsflyt, standardiserte formater og åpen kildekode. Og det er viktig at den virtuelle kjelleren man konstruerer for dette, ikke raser ut hver gang en leverandør melder product line discontinued. Og det er fint om den er robust nok til å også tåle neste generasjons publisering. For NRK starter dette med å bygge et nytt metadata-fundament for fremtiden. Vi kaller det «Origo».

Origo = metadata-revolusjon 2
Forberedelsene til Origo-prosjektet i NRK startet sommeren 2014. Origo er en idé om å bygge et fundament for metadata basert på åpen kildekode – og med tydelig struktur for metadata. Gradvis vil alle metadataene i interne kildesystemer for metadata hentes over i denne strukturen. Origo bygges med åpne databaseløsninger og data i «graf-format» (RDF). Her er teknologien hentet fra komponentene i web 3.0 – også kalt «den semantiske weben» eller «Open Linked Data».
Origo er ikke et system, men en arkitektur – en felles forankring – ; et nytt sentrum for all programproduksjon i NRK. Og når det fungerer som best, er det usynlig for NRKs journalister og usynlig for publikum. Det bare sørger for at alt det nødvendige skjer automagisk.
NRK kommer til å ha en rekke komponenter levert av eksterne leverandører i Origo – men «neste generasjons datakjeller» konstruerer vi selv.
Unik identifikasjon
Første grep i Origo er å sikre at alle programmer og komponenter av programmene har unike ID-er – og sikre at de er unike også globalt (GUID). Dette er allerede på plass i NRKs nye radioarkiv som er første del av det vi internt kaller «Metadatabanken».
En post i radioarkivet kan f.eks. se slik ut (Nitimen for 23.04.2015):
ID: 333ce4c9-ef02-47a5-adc9-7d302628cf48 (=Nitimens unike ID – for 23.04.2015)
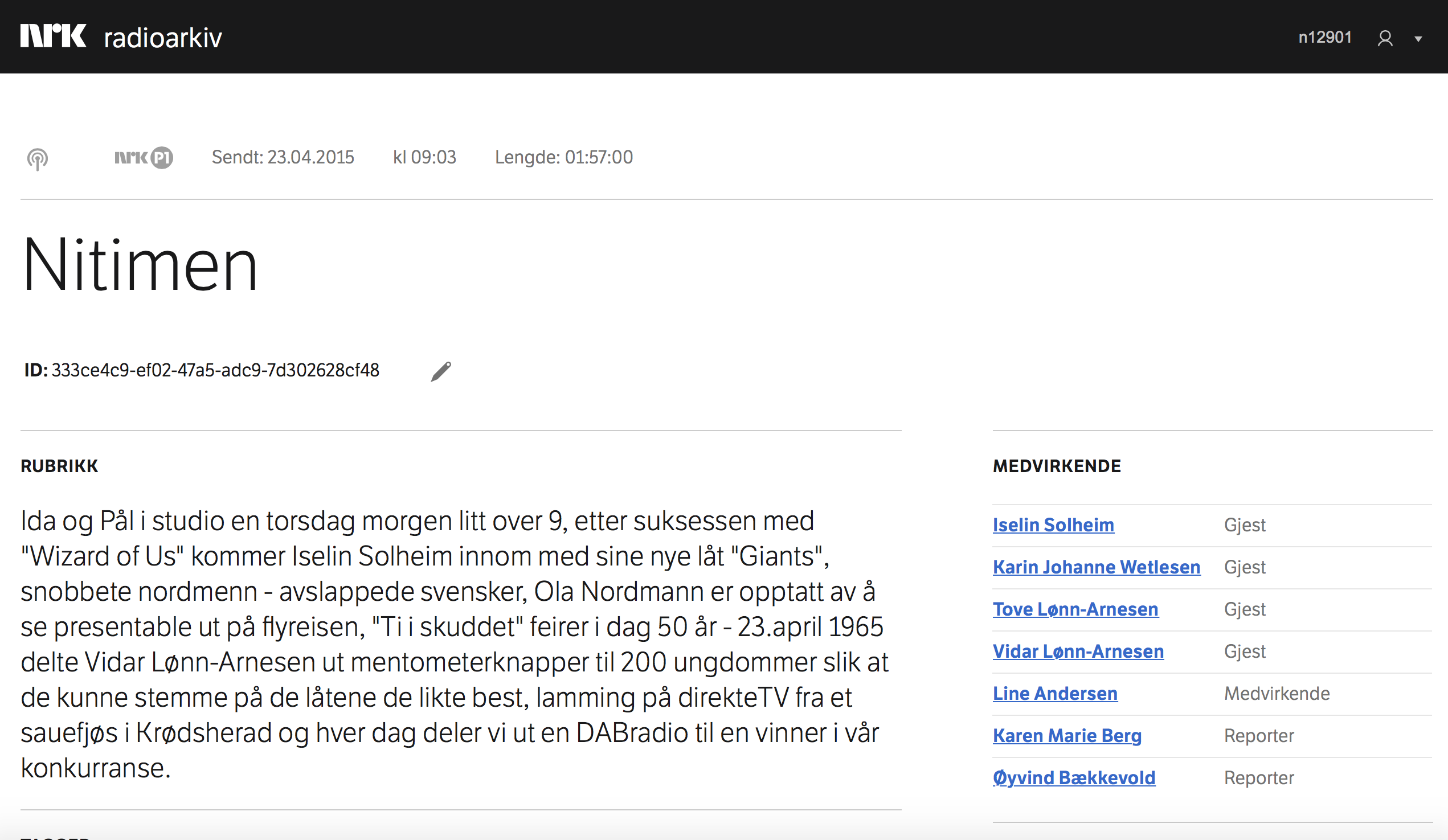
Metadata i det nye Radioarkivet er «vasket» ut i fra de gamle SIFT-arkivene som har eksistert i over 40 år. Nå ligger dataene lagret i en såkalt RDF triple store som gjør at dataene kan kobles med data i andre arkiver – og mot såkalte autoritets-registre.
Respect My Authoritah
NRK har allerede bygget et autoritetsregister for stedsnavn. Stadnamn-registeret er en viktig del av grunnlaget for NRK og met.no’s værtjeneste yr.no. Stadnamn er videreutviklet av Origo-prosjektet for også å kunne kommunisere via RDF.

Les mer om RDF og semantisk web.
NRK planlegger i tillegg å bygge autoritetsregistre for:
- Tags (i 2010 var masterversjonen av dette et Word-dokument…)
- Kategorier
- NRK personer (alle som har fått lønn av NRK siden tidenes morgen – hentet fra NRKs lønns- og personalsystem)
- NRK avdelinger (4-bokstavsforkortelser som går igjen i en masse SIFT metadata – og som ingen lenger husker hva stod for… RMUS var f.eks. «musikkavdelingen i radio»). KORK har du kanskje hørt om – Kringkastingsorkesteret. Jada, det stammer fra det samme registeret.
- Roller (Finnes publisert fra NRK gjennom standarden Gluon)
http://gluon.nrk.no/nrkRoller.xml - Hendelser
NRK ønsker å stimulere til bygging av et «nasjonalt autoritetsregister for hendelser» som kan bli til gjennom samarbeid på tvers av flere norske mediebedrifter. VG (Schibsted), TV2, Norsk Telegrambyrå (NTB), Nasjonalbiblioteket (NB) med flere har hatt det første møtet og tatt første skritt for at dette skal kunne bli mulig. Dette følger også anbefalingene rundt «open linked data» – og viser viktigheten av å dele informasjon (og dermed gjøre disse enda mer verdifulle – for alle parter).

Samarbeid på tvers
På logistisk og teknisk side er det mer som samler enn som skiller mediebedrifter. Også i andre bransjer finnes det god erfaring med å ta i bruk web 3.0/semantisk teknologi.
Firmaer som Hafslund, Statoil og Det norske Veritas er allerede i full gang med å etablere neste generasjons logistikk ved hjelp av verktøy fra den semantiske weben. En del av dette samarbeidet skjer som en del av prosjektet Optique, et stort EU-prosjekt hvor Norge har hovedansvaret. Prosjektet prøver å bygge bro mellom den tradisjonelle databaseverdenen (SQL) og semantiske spørreverktøy (SPARQL).
Venner i inn- og utland
NRK har gjennom flere år hatt et samarbeid rundt teknologi og programvareutvikling/logistikk med amerikanske CNN (Cable News Network). Samarbeidet har blant gått ut på å bygge såkalt mellomvare – programvare for enklere arbeidsflyt mellom redigerings- og publiseringssystemer. NRK har en mellomvaretype ved navn Potion som er utviklet internt (og som er en del av Origo-prosjektet). Ideen bak Potion er å skape automagisk dataflyt/arbeidsflyt på tvers av programmer og miljøer i NRK (derav navnet – The Magic Potion.)

Med TV2 har NRK et begynnende samarbeidsprosjekt rundt byggingen av Media City Bergen – Bergens nye medie-storstue, der TV2, NRK, Bergensavisen, Bergens Tidende (BT), programvarehuset Vizrt og medielinjen på Universitet i Bergen skal holde hus fra 2018. Samarbeidet er også i ferd til å utvides til å omfatte utvikling og etablering av logistikk/metadata-strukturer.
NRK samarbeider også med Netflix (en av verdens største nett-distributører) og ESPN (verdens største sportskanal – eid av ABC og Disney) om de samme områdene. Samarbeidet gjør at vi kan utveksle ideer og erfaringer – og lære av hverandre.

En del av de logistikk-oppgavene vi nå prøver å løse er så store at en og en blir mediebedriften litt for små. Men sammen er det mulig å knekke noe av «big data»-gåten. Resultatet håper vi blir at vi i fremtiden lager enda bedre programmer – og gjør dem langt enklere å finne igjen for publikum når de publiseres på nett.
Meget interessant! Det er sjelden man leser hvert ord i en nettartikkel før man haster videre. Jeg er glad for at dere publiserer slikt dybdestoff som gir god innsikt for oss mediegeeks. 🙂
Hei Andreas
Takk for veldig hyggelig kommentar. NRKbeta publisering er også god læring for oss internt for å kunne gjøre en vanskelig teknisk verden forståelig. Og dialogen med deg og andre på Beta er gull verdt for oss i videreutviklingen av løsningene. Fortsett å lese – og gi kommentarer!
GeirB
Takk for sist Geir, spennende å lese om hva du jobber med om dagen.
Spennende lesning!
Det jeg ikke helt fikk taket på var hva påsynsfiler egentlig er for noe? Er det en «lett transkodert» versjon av masterfilen (kommer ikke på noe bedre å kalle det) som kun kan spilles av internt/i en intern player?
Og hendelsesregisteret – er det et register over store og små nyhetshendelser, som f.eks. flom i Flåm e.l.?
Hei Tine Marie
Påsynsfiler er som du sier en «lett transkodert» versjon av masterfilen. I dag vil dette kunne være på mange forskjellige formater: NRKs programbank har fortsatt Windows media – andre strukturer har MPEG4 h.264 (bedre!). Radiomateriale har faktisk også «påsynsfiler» (lyttekopier) – i mp3, AAC og HE-AAC formater (avhengig av bruksområde). På live materiale som kommer inn på server lages påsyn parallelt (dvs at de kan brukes også før klippet er ferdig laget). For filer lages disse ETTER at filene er lagret på server.
Hendelsesregisteret er tenkt laget for 1. planlagte hendelser (sportsarrangementer, Nobel-pris, valg med mer) 2. ikke planlagte hendelser (ulykker, drap, terror, ras med mer). Flom i Flåm – godt eksempel på type 2 – ikke planlagte hendelser.
For øvrig takk for at du syntes at det var spennende lesing. :.)
GeirB
Hei
Dette er noe av det bedre jeg har lest på lenge!
Ja, takk til mer sånt stoff! 😀
Hei John Kristian
Takk for hyggelig kommentar. Vi planlegger mer stoff i samme gate.
GeirB
Dette var virkelig god historiefortelling om et stort og spennende prosjekt. Lykke til, Geir&Co!
Interessant lesning!
Hei!
Spennende artikkel! Kan du si noe om hvilken triple store dere bruker?
Hei Vegard
Triple store
For øyeblikket bruker vi Bigdata triple store fra Blazegraph. http://www.blazegraph.com. Men vi har prototype-testet et par andre også. Dette er hos oss foreløpig brukt kun til nytt Radioarkiv – men planen er å utvikle dette videre i løpet av året for det vi internt kaller «Metadatabanken». Metadatabanken er planlagt å inneholde alle NRK metadata. Rammeverket for Metadatabanken kommer til å bli satt opp i løpet av sommer/tidlig høst – og det kan da være at vi også kommer til å teste enda flere triple stores for å være sikker på at vi har nødvendig funksjonalitet for alle typer av data.
GeirB
Veldig godt å se slikt innhold på NRKBeta! Bra når allmennkringkasteren kan dele det som skjer bak veggene 🙂
Hei Kenneth, Frank, Are og Vegard
Takk for gode tilbakemeldinger. Det morsomme med å dele av slike erfaringer, er at det også er svært lærerikt for oss. Gode kommentarer og tilbakemeldinger gjør at vi kan lage bedre systemer for dere.
GeirB
Veldig bra Geir.
Terje…
Vet dere sikkert er leie så dere blir grønne av spørsmålet, men 1080 interlaced? Burde ikke interlaced havnet på den teknologiske skraphaugen under merkelappen «teknologi implementert ved en feil for digitale alderen»? Det begynner vel snart å kunne måles i tiår siden siste TV som støttet interlaced native ble solgt her på berget, etter at flatskjerm revoulsjonen kom. Hva annet kan interlaced brukes til i dag annet enn feilkilde og kompleksitet?
Det skinner kanskje igjennom at jeg ikke er noen fan av interlaced, men finnes det noen god grunn til å ha med interlaced i produksjonskjeden? Om det er pga analoge sendinger, hadde det ikke vært bedre å la de marginaltilfellene fått progressiv–>interlaced konvertering ved utspilling fremfor å måtte la hovedtyngden (flatskjermbrukere) måtte la alt innholdet sitt gå via interlaced?
Hei Erik
Her er vi helt enige i at interlaced egentlig burde tatt veien til skraphaugen, men infrastrukturen vår er ikke helt der enda til å gjøre et skifte. Grønn eller fiolett kabel (videokabel) tar ikke mer enn 1,5 Gbps i HD-SDI. (Denne var opprinnelig bygget for standard def – SDI (Serial Digital Interface) som opprinnelig gav 270 Mbps.) Neste generasjoner er utelukkende basert på fiber infrastruktur – og her er det nye muligheter (og hastigheter).
Les mer her:
digitalfactbook.tv/s/serial-digital-interface-sdi/
Fra 3G (3 Gbps) – må ikke forveksles med mobilplattformen 3G – er muligheten der for å kjøre formatet 1080p50 (1080=bildestørrelse 1920×1080 pixler, p = progressiv scan/non-interlaced, 50= 50 delbilder). Noen kringkastere har tatt dette i bruk i et begrenset omfang. (BBC kjørte for eksempel 1080p50 fra London-OL i 2012.)
NRKbeta planlegger mer om neste generasjons infrastruktur for video (video over IP) i en senere artikkel.
GeirB
Takker for godt svar Geir. Da skjønner man i det minste hvorfor interlaced fortsatt er med oss. 🙂
Men om man skal gjøre endring, er det ikke på tide å se på UHD? Regner med at en så stor organsisasjon som NRK bruker litt tid på å gjøre inkjøpsprosesser. Dvs at det er vel mulig at UHD begynner bli normen (eller i det minste en mulighet) innen man ser for seg å ha gjort om på infrastrukturen? Ser at UHD ikke er klart nå, men om to-fire år?
Hei igjen
NRK produserer faktisk allerede i dag en del materiale i «UHD» (hermetegn fordi oppløsningen er det samme – internt kalt 4k). Dramaavdelingen produserer alle serier på Red-kameraer (som er 4k, 5k eller 6k oppløsning). NRK har også lagd dokumentarer i 4k (22. juli dokumentaren.)
UHD er ennå ikke spesielt godt standardisert i forhold til bruk av kompresjon – i hvert fall ikke for produksjon – og distribusjon. Netflix har allerede startet med å kjøre en del serier i 4k (for nettdistribusjon) og i ca 8 Mbps som bitrate.
Men for å kunne bruke UHD (4k) eller senere UHD2 (8k) som produksjonsinfrastruktur må denne oppgraderes kraftig – og baseres på fiber (ikke kobberkabel). Det kalles nå «video over IP». (Skal skrive litt om dette senere.)
GeirB
Flott! Da ser jeg fram i mot Video over IP artikkelen. Og folkeopplysing om 4k vs UHD og UHD2. Har lært meg at det er forskjeller på 4k og UHD, men tror det er best å la ekspertene forklare forskjellene for massene.
Origo er virkelig et spennende prosjekt og det er morsomt å lese at dere samarbeider med viktige aktører i inn og utland på dette. Når MPEG21 aldri ble noen suksess (heldigvis kanskje), så er det veldig spennende med en semantisk tankegang som gir mer verdi til metadataene og ikke minst et grunnlag for bedre søkbarhet. Jeg håper dere lykkes i å spre nye og gode standarder Geir!
Ofte så mangler indeksering av programmer i nett-tv. Hva er det da som har feilet? Og hvorfor blir det aldri rettet opp i senere? (Har for øvrig sett det samme hos TV2).
Hei Diablo
Indekseringsdata kommer som regel fra produksjonssystemene inne i NRK – eller i noen tilfelle lages det manuelt etter sending. Derfor kan du faktisk oppleve at indekseringsdata blir lagt til etter at dette er publisert i nett-tv eller -radio. Det som vi imidlertid bare får tak i begrenset grad i dag, er indekseringsdata fra vårt nyhetsdatasystem. Her arbeider vi i Origo prosjektet på å gjøre dette tilgjengelig.
Hvis du ser at det mangler indekseringsdata, kan dette skyldes feil i metadataflyt – som vil bli rettet opp så snart systemer «synker» seg opp. Men det kan selvsagt også skyldes at noen manuelle ledd svikter i «kampens hete». Vi arbeider for at manuelle rutiner skal bli mindre viktig, og at det meste av indekseringsdata kommer med automatisk (der metadata finnes).
mvh
GeirB
Bare lurer, har dere noe slags system for vannmerking av videoer i systemet deres? (Har merket at alle arkiv-videoer som før ikke hadde vannmerke har det nå.)
Jeg har ventet på svar i 5 måneder nå :/