Vi har laget et program som transkriberer intervjuer for deg, og kildekoden er lagt ut under MIT-lisens. Det er en hake, men den kan vi komme tilbake til senere.
Tidligere i år fortalte journalistene at de brukte timevis, om ikke dagevis, på å transkribere intervjuer.
Det fikk oss til å bruke noe vi kaller innovasjonsdager, altså 24 timer lange hackathons der hvem som helst i organisasjonen kan komme med ideer og få bygget en prototype eller demo, til å prøve å løse problemet.
Med den rivende utviklingen vi har sett innen maskinlæring de siste årene, ønsket de å se på muligheten for å automatisere tale-til-tekst-prosessen, slik at de kunne bruke tiden sin bedre.
24 timer senere hadde vi en demo klar, og lanserer i dag løsningen med åpen kildekode.
Først, litt historie
Drømmen om at maskiner skal forstå oss, er ikke ny. Liker du ikke historie og artige anekdoter kan du hoppe ned til mellomoverskriften «Vår løsning».
Allerede på 1950-tallet jobbet Bell Laboratories med en maskin de kalte Audrey, the Automatic Digit Recognizer. Som det fremgår av navnet, kunne denne maskinen forstå tall. Den kunne tolke tall fra 0 til 9 med over 90% nøyaktighet, vel og merke når oppfinneren selv snakket.
Når andre snakket var nøyaktigheten rundt 70-80%. Man måtte også gjøre korte opphold mellom hvert tall, men det var likevel en aldri så liten revolusjon og starten på noe langt større.
I 1962 lanserte IBM maskinen Shoebox på Verdensutstillingen i Seattle. Den kunne i tillegg til tall, forstå 16 engelske ord og utføre enkel aritmetikk. Som sin forgjenger, baserte også denne maskinen seg på maler, der enkeltord ble sammenlignet med lagrede lydmønstre.
På 1970-tallet utførte DARPA et 5 år langt forskningsprosjekt i samarbeid med Carnegie Mellon-universitetet, der resultat ble maskinen Harpy. Den kunne gjenkjenne drøyt 1000 ord (omtrent som en 3-åring), og var det første systemet som kunne gjenkjenne setninger.
I det man går fra å gjenkjenne ord til setninger, får man flere utfordringer.
Blant annet må man forholde seg til oronymer – setninger eller ord som høres like ut, men som betyr forskjellige ting. Et eksempel er give me a new display, som høres helt lik ut som give me a nudist play. Det samme gjelder euthanasia (form for aktive dødshjelp) og youth in Asia.

En måte å takle setningsforståelse og kontekst på, er å bruke statistiske metoder. Det vil si, hva er sannsynligheten for at et ord kommer fra en ukjent lyd?
Dette var noe IBM jobbet med på 1980-tallet, da de lanserte maskinen Tangora. Den var oppkalt etter Albert Tangora, verdensrekordholderen i hurtigskriving på den tiden. Dette var det første systemet som ikke var avhengig av maler og ferdige lydfiler, og maskinen kunne gjenkjenne rundt 20 000 ord. Hver person måtte trene opp systemet i rundt 20 minutter før det kunne tas i bruk.
På 1990-tallet kom nye og raskere mikroprosessorer, som gjorde mer avansert programvare mulig. Dragon kom i 1997 med det første systemet som kunne gjenkjenne kontinuerlig tale (man slapp dermed å pause mellom hvert ord). Systemet kunne transkribere 100 ord i minuttet, men prislappen var på hele 9 000 dollar.
På tidlig 2000-tallet hadde utviklingen nådd et platå, og det var ikke før Google i 2008 kom med Voice Search at utviklingen igjen skjøt fart. Enorme mengder treningsdata, nevrale nettverk og beregninger i Googles datasentra gjorde det mulig å få et helt nytt nivå av presisjon.
Vår løsning
Etter å ha sett på hvilke transkriberingsløsninger som finnes på markedet, gikk vi til slutt for Googles tale-API. I kombinasjon med React (et JavaScript-bibliotek for å lage interaktive brukergrensesnitt) og Firebase (en samling av skytjenester, som fillagring, databaser og skyfunksjoner) klarte vi å få en prototype opp på beina i løpet av 24 timer.
Brukeren starter med å laste opp en lydfil og velge hvilket språk som snakkes. En skyfunksjon plukker opp dette, og deretter skjer en tredelt prosess:
1. Transkoding
Googles tale-API krever lydfiler i mono for å fungere. Lydfilen blir derfor først transkodet. Til dette bruker vi FFmpeg, et åpen kildekodebibliotek for lydbehandling. Etter at lydfiler har blitt omgjort til FLAC i mono, lagres den i Firebase Storage.
2. Transkribering
Neste steg er å transkribere lydfilen. Her brukes Node.js-klienten til Google Speech, som for tiden er i alfautgave og dessverre temmelig ustabil til tider.
3. Lagring
Når vi får svar fra tale-APIet, lagrer vi alt i Firebase Realtime Database. Vi lagrer også tidskoder per ord, slik at disse kan markeres i gult i det lydklippet spilles av i nettløsningen.
For å vise resultatet er første episode av podkasten To hvite menn et godt utgangspunkt. Her er diksjonen stort sett god, men selv da er det noen steder ord feiltolkes eller utelates:
Erfaringer
Det er vel ingen overraskelse at et lite språk som norsk ikke får den samme kjærligheten som engelsk. Forskjellen er tydelig, kanskje spesielt siden norsk ikke har tegnsetting (komma og punktum) ennå. Dette vil forhåpentligvis endre seg i de kommende månedene.
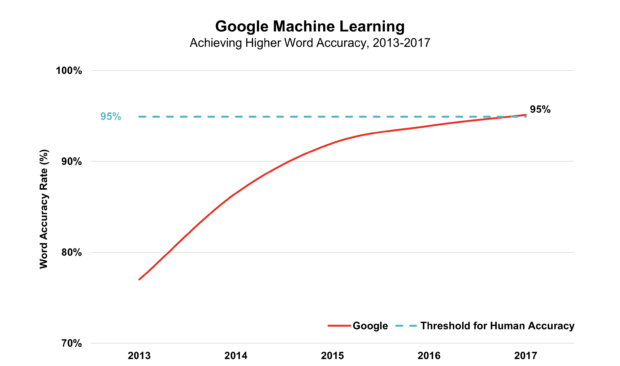
Google har sagt at Google Home (som bygger på samme teknologi) kommer i salg i Norge. Utviklingen peker i hvert fall i riktig retning. Fra 23% feil i 2013, var denne nede i knappe 5% i fjor, vel og merke for engelsk.
Tale-API-et klarer heller ikke å skille på forskjellige personer som snakker. Det gjør at det fort blir rotete om flere snakker i munnen på hverandre. Den takler heller ikke forskjellige språk i samme lydfil.
Sluttresultatet blir også dårligere om det er bakgrunnsstøy eller om personene som snakker har ulik avstand til mikrofonen.
Alt i alt er konklusjonen at det per i dag ikke er mulig å bruke transkriberingene verbatim til artikler eller lignende, hverken for engelsk eller norsk.
Men den store fordelen er at et flere timer langt intervju plutselig er søkbart, i hvert fall til en viss grad. For journalisten blir dette først og fremst et verktøy for å finne igjen interessante partier som hun ønsker å lytte til igjen under arbeidet med å skrive artikler.
Det finnes andre transkriberingsløsninger på markedet som støtter norsk, som Microsofts Bings tale-API og norske Max Manus, men de har vi ikke hatt tid til å utforske.
Åpen kildekode
Undertegnede presenterte prosjektet på årets NONA-konferanse, og tilbakemeldingene fra publikum var tydelige på at dette er noe flere kunne tenke seg å bruke.
NRK ønsker derfor å tilgjengeliggjøre koden vi har laget som åpen kildekode med MIT-lisens, slik at hvem som helst kan ta det i bruk. Vi håper med det at flere ønsker å være med å videreutvikle dette prosjektet.
Koden for både front-end og skyfunksjonene ligger på Github. Det er fortsatt mye som gjenstår, og vi tar i bruk issues for å jobbe videre med dette.
Kilder:
Pao vaigne tao oss me «løgne» talemaol – kelein funka danna når e snakka dialekt dao?
Ein ting er jo «oss» som snakkar inn i mikrofonen med mål om å snakke tydeleg og poengtert, men eg veit jo stort sett kva eg sjølv seier – det er intervjuobjekta mine, dei som faktisk må delimprovisere svara sine som blir verst for maskiner som denne, ser eg for meg.
Ellers – endeleg! Snart treng eg kanskje ikkje å køyre min vande «skru ned farta på opptaket til 70 % og transkriber medan du høyrest ut som du er full»-trikset mitt lengre.
Har ikke prøvd det på dialekter, men jeg antar det vil bli stygt. Enten vil den ikke oppfatte noe (støy?) eller den vil gjette helt feil
Jeg testet systemet på et NTNU-prosjekt hvor de har et av Esops fabler innlest på et femtitalls ulike norske dialekter. Resultatene var noe varierende, men ikke helt håpløse.
Det lover jo godt!
Da PCene begynte å komme på slutten av 1970-tallet var det til å begynne med vanskelig å finne anvendelsesområder. Det fantes utrolig mye rart utstyr og programvare, regnekraften tatt i betraktning, og tidsskriftet BYTE hadde en artikkel om en kar som hadde brukt et system som kunne gjenkjenne 64 kommandoord til å styre utganger som f.eks. aktiverte motoren som åpnet inngangsdøra, eller åpnet et spjell så det falt mer finhogget ved ned i vedovnen hans — smarthus anno 1980.
Systemet handterte 64 forhåndsdefinerte kommando-ord, og gjenkjente kun stemmen til den som hadde stått for «opplæringen». Det ble gjort forsøk på å øke vokabularet, men det ble for mye feil. Om jeg husker rett hadde de mer suksess i å akseptere ulike stemmer, ikke bare «læreren».
Jeg burde grave fram det gamle BYTE-bladet fra kjelleren for å se hvilke enorme framskritt vi har gjort på rundt førti år. Her går utviklingen med stormskritt!
Anbefaler å ta en titt på Trint.com. De støtter idag Dansk og Svensk. Så med litt hjelp så kan de vel prioritere Norsk også.
Selskapet fokusrer på journalister. Regner med at de bruker google i bakgrunnen.
Ser fram til den dagen de køyrer heile radioarkivet (og gjerne lydsporet til fjernsynsarkivet òg) til NRK gjennom ei slik løysing, og legg ein enkel søkemotor oppå det heile.
Så kan publikum søka og finna interessante program om eit gitt tema (eller program som nemner eit gitt sitat). Det kan til og med brukast for å automatisk finna program som innhaldsmessig liknar på kvarandre. Talegjenkjenninga treng ikkje vera perfekt for at dette vil vera svært nyttig!
Hvordan foregår teksting av programmer med andre språk? Er det helt manuelt? Hvis det er tilfelle, kunne denne teknologien vært brukt til det?
Dette er superinteressant. Men for meg som transkriberer langt mer enn jeg programmerer, klarer jeg ikke helt å skjønne hvordan jeg kan sette opp en løsning som funker (hvordan kommer jeg dit at jeg kan sende en fil og få transkripsjonen i retur?). Jeg har lastet ned koden, laget databaser osv i Firebase, men jeg skjønner ingenting. Trenger jeg et program for å kjøre alt sammen?