
Hvordan får man oversikt, når data om nesten 100 millioner regninger fra landets spesialister og fastleger dumper ned i innboksen?
(Saken er oppdatert.)
Den 22. mai 2019 publiserte NRK Brennpunkt dokumentarfilmen «Pengespesialistene», som er det andre dokumentarprosjektet basert på et datasett med detaljerte data om refusjoner fra det offentlige til landets leger.
I den siste filmen titter vi enda nærmere på legene som arbeider innenfor spesialisthelsetjenesten, etter å ha konsentrert oss om fastlegene i den forrige filmen, «Legekoden» fra 2018.
Det startet allerede i februar i fjor. Da ba vi helsemyndighetene om innsyn i data om aktiviteten til landets fastleger. Data om hvordan 15 milliarder offentlige kroner fordeler seg på 9 700 leger i Norge over tre år. Her fantes bestefars inngrodde tånegl, lillebrors armbrudd og fars røykeavvenningsprat med legen.
Senere be vi om få få utvidet uttrekket fra Helfo til også å omfatte 2018. Vi ba også om innsyn i data om de såkalte avtalespesialistene. Dermed satt vi med data om til sammen 28 milliarder helsekroner over fire år, fordelt på totalt 12 156 leger.
Sjenert fireåring
I journalistisk sammenheng, snakker vi av og til om å «intervjue dataene», ut fra ideen om at et datasett skjuler journalistiske poenger som man kan forløse ved nærmest å gå i dialog med materialet gjennom såkalte SQL-spørringer. Det er en ganske god beskrivelse — men bare hvis du tenker deg intervjuobjektet som en sjenert fireåring som svarer i enstavelser.
Ved å gjøre kjøringer på de ulike takstene, kunne vi se hvilke leger som utmerket seg med mange regninger til staten. Etter å ha kartlagt de som var «grådigst», kunne vi gå videre til postjournalene til Helfo. Her kunne vi så be om innsyn i alle vedtak som var blitt gjort på de som toppet statistikken. Når vi så fant ut at det fantes vedtak om tilbakebetaling på flere av disse begynte det virkelig å bli interessant. Disse dokumentene fortalte oss igjen om takstbruk både på og over kanten av det lovlige.
Det finnes etter hvert flere journalister som tar i bruk databaseløsninger og SQL når de skal få orden på store datamengder, slik som i dette tilfellet er Excel ikke lenger kraftig nok. La meg derfor gå steg for steg igjennom hvordan vi gikk fram for å kartlegge dataene.
Databasen KUHR
Hver gang du har vært hos fastlegen eller spesialistlegen, sender hun en regning til HELFO, som er den såkalte «ytre etaten» til Helsedirektoratet. HELFO har ansvaret for pengeutbetalinger, blant annet til landets spesialister og fastleger. På regningen er det ført opp en eller flere takstkoder, som hver utløser en tariffestet sum. Dataene blir tatt vare på i et datasystem med det interne navnet KUHR (Kontroll og utbetaling av helserefusjoner).
Taushetsplikten er åpenbart et tema i forbindelse med denne typen opplysninger. Direktoratet gikk i dialog med NRK, og laget et tilpasset (aggregert) datasett uten noen form for pasientinformasjon. Risikoen for bakoversporing av pasientenes identitet var helt eliminert ved at hver lege kun var ført opp med samleposter for antall takster og summert refusjonsbeløp for hver takst. Slik kunne forvaltningen imøtekomme et ellers legitimt innsynskrav, uten å risikere brudd på taushetsplikten.
Filen vi først fikk, besto av 1,5 millioner linjer. Én linje per takstkode per lege per praksis per år, med antall og summert kronebeløp. Den dekket årene 2015, 2016 og 2017.
For å få noe ut av dette datasettet, måtte vi gå detaljert til verks. Du får ingen tabell over journalistiske poenger fra enkeltspørringer. Det er «fireåringen» som svarer, og det er krevende å vite akkurat hva han svarer på.
Helsesjekk av helsedataene
Vi må bli kjent med dataene. Det er fort gjort å snuble ned i noen riktig mørke fallgruver når man bruker aggregerte datasett som utgangspunkt for videre kjøringer. Det er for eksempel viktig å være klar over hvilke verdier som
Vi gjorde en rekke kontrollutregninger, og brukte mye tid på å finne igjen våre egne tall hos andre kilder, gjerne i offisielle rapporter og statistikker. Hadde tallene våre skilt seg vesentlig fra andres utregninger, måtte vi ha kommet til bunns i årsaken.
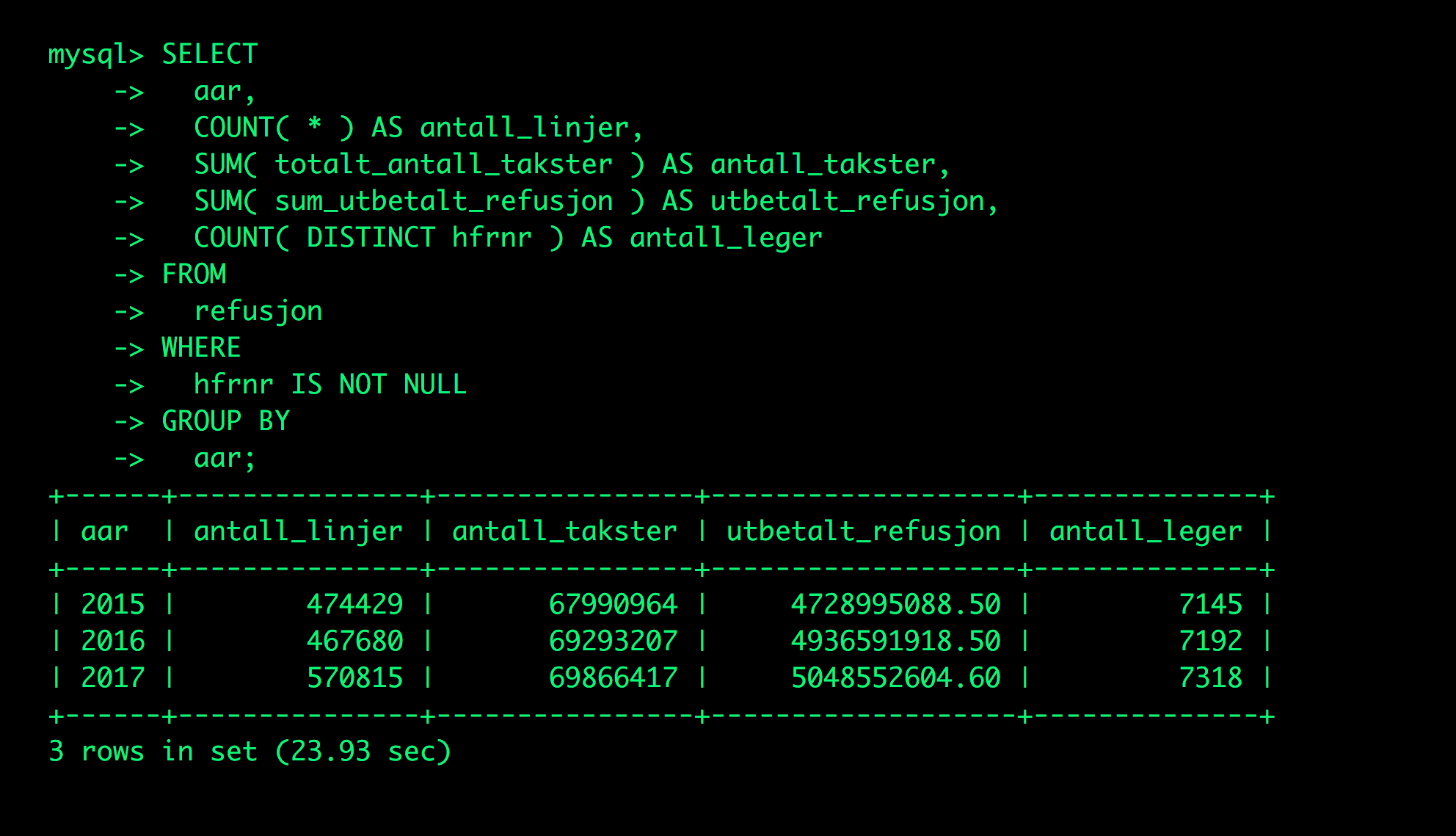
Senere ba vi om å få enda et uttrekk med antall pasienter per lege, kronebeløp og antall regninger. Fra dette siste datasettet, kunne vi få et bredere oversiktsbilde over materialet:
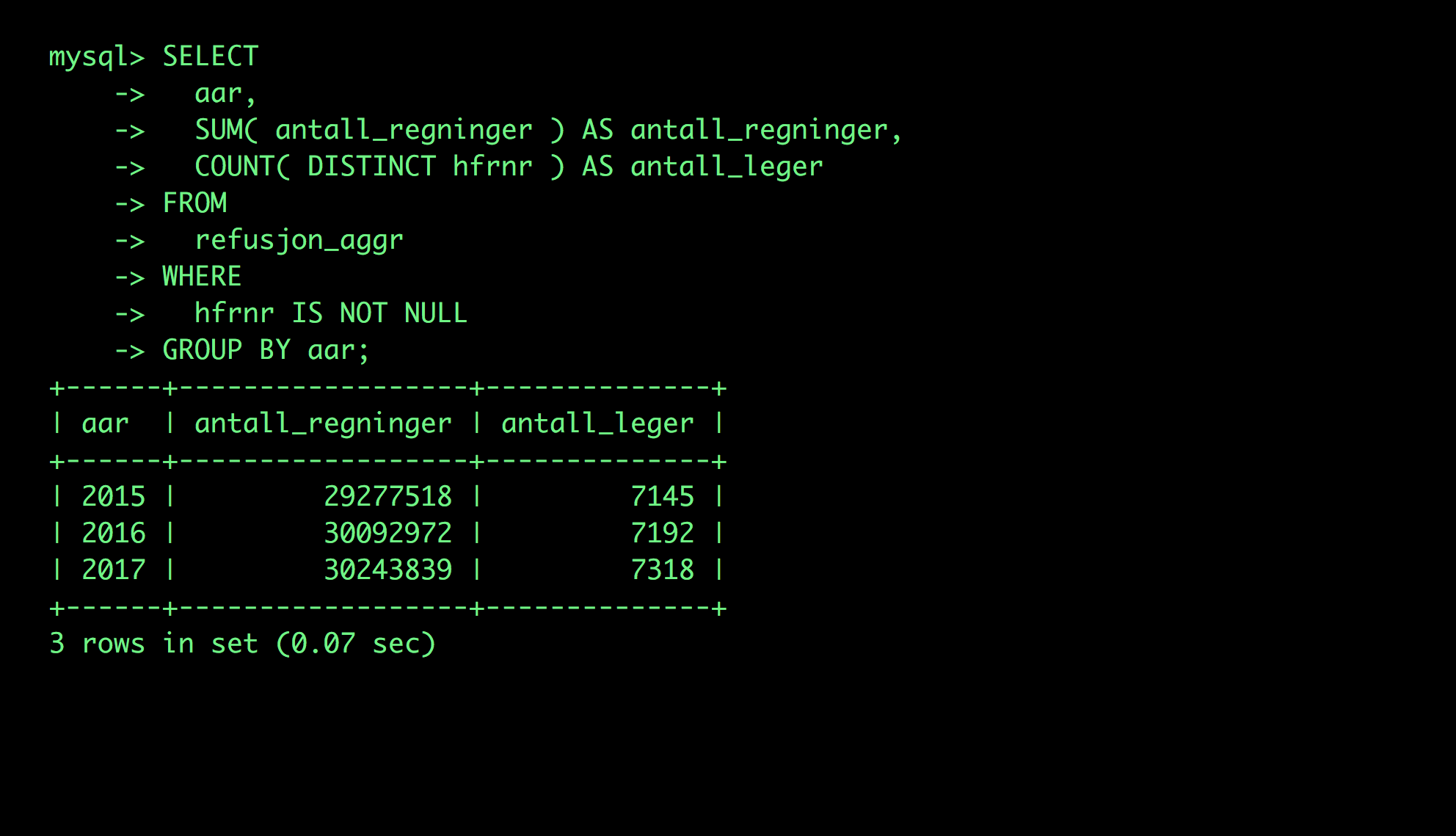
Dette stemmer i grove trekk overens med HELFOs egne måltall. I den innledende fasen brukte vi mye tid nettopp på kjøringer som dette — for å forstå tallene.
Å «pimpe opp» MySQL
De første spørringene dreide seg som sagt om å få oversikt. De fleste databasemotorene har innebygd støtte for enkle statistiske funksjoner, slik som gjennomsnitt og standardavvik. Vi har «pimpet opp» MySQL med flere programutvidelser, blant annet MySQL Infusion UDF av Robert Eisele, som også gir oss funksjoner som lettere finner for eksempel persentiler (herunder også median) og typetall.
De nyeste versjonene av MySQL og dens avlegger, MariaDB har for øvrig en rekke innebygde funksjoner som langt på vei overflødiggjør behovet for å installere programutvidelser for å gjøre enkle statistiske kjøringer.
Fastleger har varierende antall pasienter på listene sine. Disse listene er heller ikke alltid stabile over tid. Derfor måtte vi komplettere datasettet vårt med informasjon fra fastlegedatabasen til Helsedirektoratet. En ny innynsbegjæring ble sendt, der vi ba om lengden på pasientlistene for hver fastlege i Norge. Informasjonen finnes allerede fersk og tilgjengelig på nettet, men vi ønsket de historiske tallene for 2015, 2016 og 2017, slik at de kunne holdes sammen med KUHR-dataene.
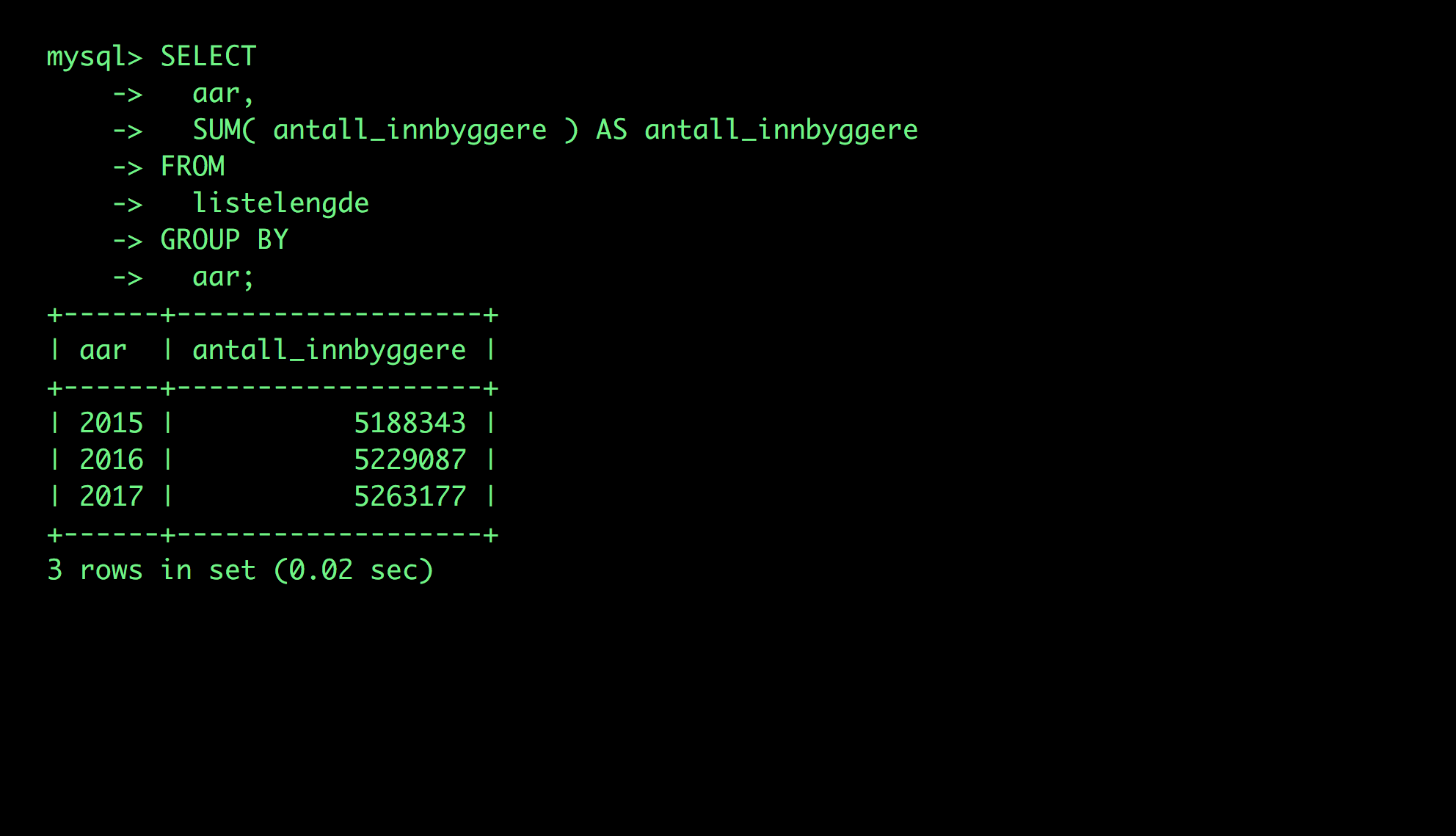
Vi fikk for eksempel bekreftet fra Helsedirektoratet at ingen enkeltpersoner kan stå på mer enn én fastlegeliste om gangen. En rask faktasjekk var da å kontrollere at det summerte antallet pasienter på fastlegenes lister stemmer med det offisielle folketallet i Norge, noe vi enkelt kan sjekke opp mot SSB.
Vi startet analysearbeidet med å splitte opp (normalisere) dataene og fordele dem på i alt seks tabeller. Da går det lettere og raskere å kjøre de mer komplekse spørringene mot datasettet:
-
lege
En rad per lege, identifisert med offisielt autorisasjonsnummer (HPR-nummer) i helsepersonellregisteret.
-
praksis
Én rad per legepraksis, identifisert med organisasjonsnummer.
-
lege_praksis
Siden noen leger er knyttet til flere praksiser må vi ha en oppslagstabell som kobler legen til en eller flere praksiser.
-
refusjon
Hver rad inneholder data om bruken av én takstkode knyttet til én enkelt lege ved én bestemt praksis i løpet av ett år.
-
refusjon_aggr
Aggregert utgave av tabellen over, med antall pasienter per lege, samlet refusjonsbeløp og antallet regninger.
-
listelengde
Historisk uttrekk fra fastlegebasen, med antall innbyggere på legelistene til hver fastlege for årene 2015, 2016 og 2017.
Hjemmesnekret rapportverktøy
Etter hvert som kontrollkjøringene og den pågående dialogen med helsemyndighetene fikk oss til å føle oss sikre på at vi hadde forstått dataene riktig, kunne vi begynne å drille oss ned i datasettene.
SQL-spørringene ble lange og mange. Vi endte opp med en SQL-fil på over 9 000 linjer med spørringer. Vi gjorde både statistiske kjøringer, så vel som mer målrettede undersøkelser. SQL-spørringene ble konvertert til en mer leselig PDF-fil ved hjelp av det hjemmesnekrede skriptet mkres som vi har utviklet for intern bruk (advarsel: usedvanlig fæl kildekode), og som bruker tekstformateringsspråket LaTeX sammen med kommandolinje-verktøyet pdflatex for å produsere en PDF-rapport for det menneskelige øye.

Rapporten dannet grunnlaget for den videre undersøkelsen, og den vokste stadig, etter hvert som vi la inn nye kjøringer. I skrivende stund er den på 139 sider.
Ploticus
Noen av kjøringene ønsket vi å visualisere. Programvaren Ploticus kom oss til unnsetning — en gammel og god applikasjon for å generere stolpediagrammer og annen grafikk.
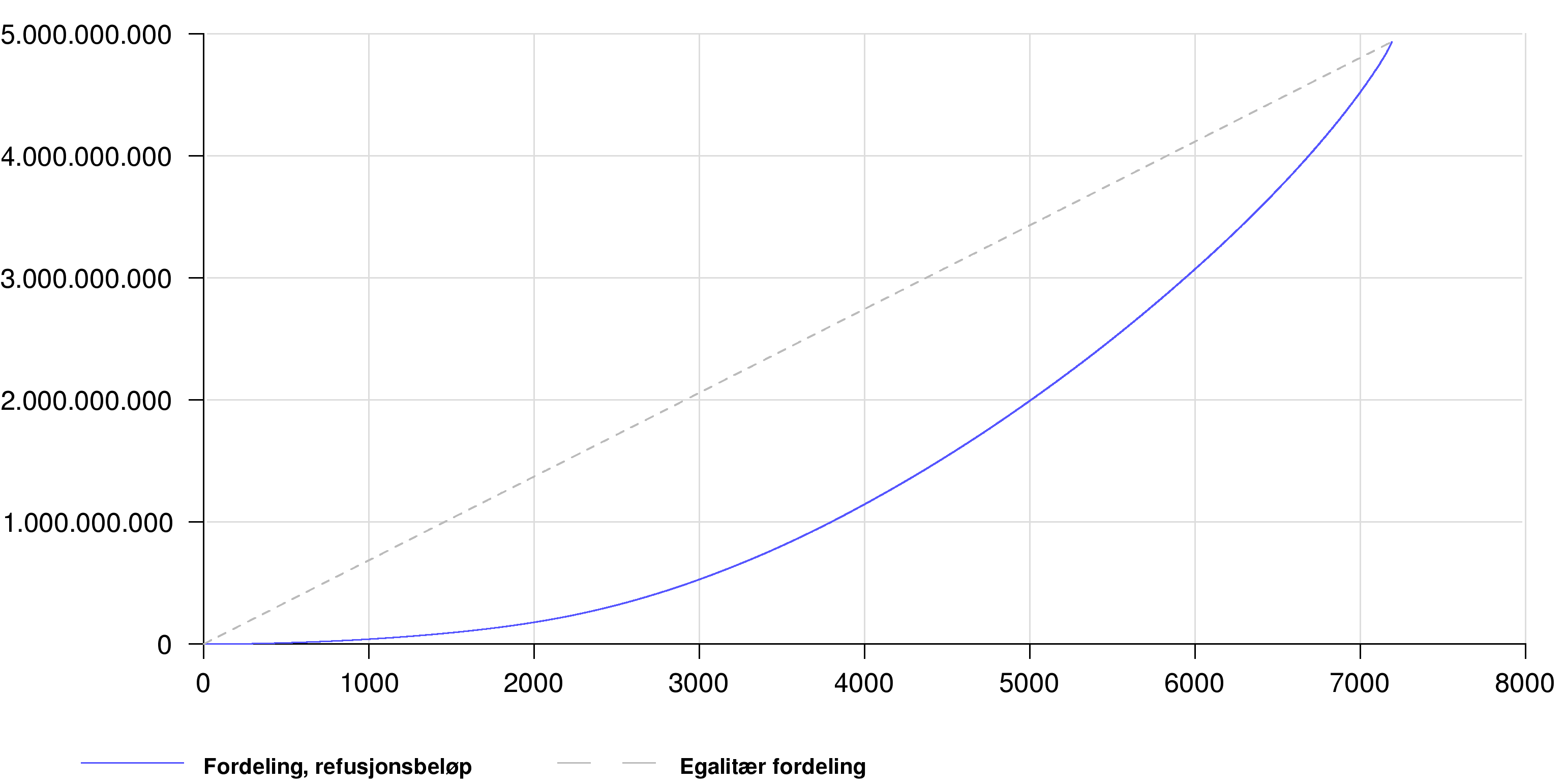
Dette er et eksempel på en av spørringene vi gjorde mot dataene. Vi ønsket å se på hvordan pengene faktisk er fordelt blant legene, og fikk Ploticus til å tegne en såkalt lorentzkurve, som viser at de øverste 25 prosentene av legene får omkring halvparten av pengene. Y-aksen viser beløp, og X-aksen viser antall leger.
Tilgangen til store data fra det offentlige blir stadig bedre, etter hvert som forvaltningen blir fortrolig med de reglene som gjelder for utlevering av sammenstillinger fra databaser (for eksempel med offentlighetsloven § 9). I tillegg blir også fagsystemene i det offentlige stadig kraftigere og bedre, slik at dataeksport og -utlevering ikke lenger kan sies å være en tung og krevende jobb for embetsverket.
For dem som bruker virtualiseringsprogramvaren Docker, har vi laget et image med en ferdigkompilert utgave av MySQL med blant annet Infusion UDF og et knippe andre forbedringer. Også rapportverktøyet krever mye programvare for å fungere. Derfor har vi også her laget et Docker-image der mkres er installert sammen med all nødvendig programvare for å bygge PDF-filer fra SQL-skript.
- Her kan du se «Pengespesialistene» fra 2019 i sin helhet
- Her kan du se «Legekoden» fra 2018 i sin helhet
***
Saken er oppdatert i forbindelse med at NRK 22. mai 2019 publiserte «Pengespesialistene», som er en ny dokumentar basert på samme metode og datagrunnlag.
Og vi som trodde at griskhet og grådighet og svindel ikke fantes blant legene, som er opptatt av sin legegjerning og ikke med å svindle staten for å bli enda rikere ?? Nå nei, og nå er det bevist.
Aiaiaiai…mere av denne typen artikler!
Bruken til dere i NRK her virker grei og fornuftig, men det er likevel veldig skremmende å se hvor mye data som faktisk samles. I tillegg.. uthenting av data høres ut til å være tilpasset formålet, men det er ingen fysiske hindringer som forhindrer 2 eller flere å sammenkjøre sine datasett selv om dette antageligvis ville vært ulovlig. Når man hører at landet skal «digitaliseres» som det kalles og dere skriver at den offentlige tilgangen til data skal bli «bedre», så er det desto skremmende. Det er som en nesten bør unngå å gå til lege da disse besøkene slett ikke er så konfidensielle som vi ledes til å tro. De fleste tror besøket er kun mellom lege og deg som pasient, men med alle disse dataene som lagres så er det jo åpenbart ikke tilfellet.
Hei,
Espen må nok svaret på det konkrete i dette tilfellet, men du har helt rett i at samkjøring av ulike datasett kan deanonymisere. Det er også en potensiell risiko for at noen får systemtilgang og slik kan hente ut pasientdata over tid.
Denne Wired-saken rører med hva statlige aktører har kapabilitet til.
Hei, innspillene du kommer med er både viktige og aktuelle.
Her er det avgjørende å sette et skille mellom hva som anses for offentlig informasjon, og hva som ses på som beskyttelsesverdig informasjon.
Det er viktig med åpenhet og innsyn i forvaltningen. Hensikten med offentlighetsloven, er å sikre allmennhetens muligheter til å føre kontroll med offentlig virksomhet, og å følge politiske og administrative prosesser. Innsynsretten er avgjørende for deltakelse i demokratiet, og balansen mellom personvernet (gjerne uttrykt gjennom ulike taushetsbestemmelser) og åpenhetsprinsippet er behandlet flere steder i lovverket – blant annet i personopplysningslovens § 7.
Før fantes det meste i form av dokumenter på papir eller som kartotekkort. I dag er det stadig flere data som kun er tilgjengelig digitalt. For noen år siden ble offentlighetsloven utvidet til å omfatte retten til å kreve sammenstillinger fra databaser. Dette var en helt nødvendig modernisering av lovverket, men bestemmelsen endret ikke på situasjonen i forhold til taushetsbelagt informasjon. Taushetsbelagte oppløysninger skal ikke under noen omstendighet utleveres, og koblingsfaren er en del av vurderingen forvaltningen er pålagt å gjøre før de utleverer data.
I vårt eksempel er forholdet til personvernet uproblematisk. Datasettet er i aller høyeste grad offentlig informasjon. De beskriver den konkrete fordelingen av 15 mrd skattekroner. Som nevnt i artikkelen, gjør aggregeringen det teknisk umulig å assosiere enkeltpasienter med dataene. Dette var selvfølgelig en viktig vurdering HELFO og Skattedirektoratet gjorde før de utleverte datafilen.
Legene, som på sin side er fullt identifisert med navn og autorisasjonsnummer, opptrer i denne sammenheng som offisielle personer som forvalter fellesskapets midler. Det finnes andre eksempler på offentlige datasett som sikkert setter problemstillingen du tar opp mer på spissen enn legedataene våre.
En av mine metoder er jo nettopp å koble data fra ulike kilder. Dette gjør jeg for å finne ukjente sammenhenger, og kanskje avdekke misforhold som ellers forblir i det skjulte. Noen sjeldne ganger hender det at vi utilsiktet kommer nær grensen for hva som kan være personlig informasjon om enkeltindivider, men dette er ikke noe nytt i journalistisk sammenheng. Det er heldigvis stor forskjell på hva pressefolk samler inn av informasjon, og hva vi publiserer. «Vær Varsom»-plakaten har klare publiseringsregler. Presseetikken stopper oss som oftest lenge før jusen.
Man skal være veldig forsiktig med å akseptere restriksjoner på innsyn og tilgang til offentlig informasjon ut fra bekymringer om «hva du kan bruke» opplysningene til. En slik argumentasjon kan overføres på det aller meste av opplysninger som måtte forefinnes i offentlige arkiver. All informasjon kan i teorien misbrukes. Da politiet mente at offentlige skattelister gjorde det enklere for kriminelle å finne millionærer, kunne de etter mitt syn like gjerne ment at vi burde fjernet Holmenkollåsen og Nesøya fra offentlige kart, siden også disse dataene i praksis gjør det enklere for kriminelle å finne formuende ofre…
Noen av de mest sensitive dataene jeg har jobbet med, kommer faktisk ikke fra offentlig forvaltning, men fra sosiale medier. Informasjon som folk frivillig har lagt ut om seg selv og sine venner, og som vi systematiserer og analyserer. Dette var noe vi gjorde en del i forbindelse med research av høyreekstreme nettverk etter terrorhandlingene 22. juli 2011, for å nevne et eksempel.
Er PDF-rapporten dere lagde offentlig tilgjengelig?
Hei. Rapporten er en tidlig undersøkelse, som vi dessverre ikke kan publisere. Den tar blant annet for seg ulike hypoteser, og involverer et betydelig antall navngitte enkeltleger (det går for eksempel på tidsbruk, overforbruk av takster, høye utbetalinger etc.).
Vi kan ikke publisere noe som urettmessig ville ha kastet mistanke mot dem som slett ikke har gjort noe galt. Det ville vært urimelig og hensynsløst overfor dem det gjelder, og også brudd på presseetikken.
Spennende! Hvor stor i filstørrelse ble den endelig MySQL databasen?
Jeg er usikker på hvordan dette skal karakteriseres, men det ser unektelig ut som trygdejuks av verste sort. Og er det juks er det også fullstendig uakseptabelt at den ansvarlige slipper unna med det. Spesielt tatt i betraktning, at vanlige folk straffes svært hardt for langt mindre. Det SKAL være likhet for loven, og dersom det ikke er det, så har vi et alvorlig demokratisk problem i landet vårt.
Nå er det en gammel kjennsgjerning at korrelasjon ikke nødvendigvis tilsier kausalitet. Det kan jo hende at de legene som har de sykeste pasientene får mest i refusjoner og i tillegg skriver ut flest sykemeldinger? Altså to effekter av samme årsak. Det mest interessante med denne artikkelen er likevel at det lønner seg for legene å skrive ut sykemeldinger og resepter, mens det kan være mer lønnsomt for samfunnet at det brukes mer tid på andre ting. Da har vi noen systemfeil. Arbeidet er likevel en veldig god start på å gå dypere inn i materien. Det store elefanten i rommet er jo den fantastisk gode sykelønnsordningen vi har, og hvilke utslag den kan gi dersom folk misbruker den.
Dette er deling av kunnskap en statskanal verdig, helt suverent.
Ad sykmeldinger, dere skriver:
«For hver lege har vi dividert antallet sykemeldinger med antall unike pasienter vedkommende krevde betaling for i løpet av året. Dette gir oss relativt antall sykemeldinger i forhold til pasientmengde.»
Hvordan er «antall sykmeldinger» definert? Har dere telt hver gang det er brukt takst L1 eller er «sykmelding» et sykmeldingsløp (som ofte kan bestå av gjentatte konsultasjoner, flere forlengelser, med tilhørende bruk av takst L1)?
Og er det korrekt at det er UNIKE pasienter som er nevneren? Eller er det konsultasjoner?