
tl;dr; When testing resiliency we seek to understand how an application reacts to simulated transient errors under high load and how it can gracefully recover. If we tie the configuration of transient-error simulation to the application in such a way that we have to redeploy to change configuration, we will reset memory, TCP state, threads and all application state. Then we will not be able to see how the application itself would recover without an external actor forcefully killing and restarting it. Using feature-toggles we can introduce and remove errors in the application under load without redeploying, enabling us to see how the application itself will recover.
Modern web applications operate in a complex environment, with transient dependencies on services outside of our control. There are many ways in which these dependencies may affect the performance of our applications:
- Upstream services may start failing or take a long time to respond.
- Downstream services may change how they are consuming our services, e.g. by increasing the number of requests overall or starting to make requests in bursts.
- Cloud infrastructure might change behavior.
Most applications work well on a sunny day, but to achieve high reliability we need to design for bad weather. If we want our applications to continue working reasonably well in the presence of errors, we must design for it – and then run experiments that verify that the design works as intended.
Application state and limited resources
Even applications we typically call stateless have state. They might have some sort of cache, maybe an HTTP proxy bundled with the application or a memory cache. Even if they have no cache, or use an external cache such as Redis, they still have state. A .NET application will have Just-In-Time compiled because it has been running. It will have a number of threads in the thread-pool adjusted to the load they operate under. It will have opened a number of TCP connections to other services, using any number of sockets. Maybe it has opened a number of database connections.
In a stateless application, all these will reset on a restart, and after a certain time reach a new steady state with normal operation. However, what we are looking for are transients. If we have to wait for an external application such as Kubernetes or an Azure service to handle detecting and restarting faulting applications for us, there are transient effects at play that do affect the operation of the service. The external application needs to see that the application is struggling, kill it, create a new one and that service needs to start from scratch and accept new traffic.
Much of the state involves limited resources that are necessary to communicate with external dependencies. If we want our applications to be healthy and run well even in the face of transient errors, we need to verify that we handle these resources economically and correctly. Modern infrastructure can and should restart services that leak memory or sockets to maintain operation even if our applications are faulty, but that does not mean we should not try to improve how these applications work.
Poor resource handling may well lead to a pathological cycle of application behavior:
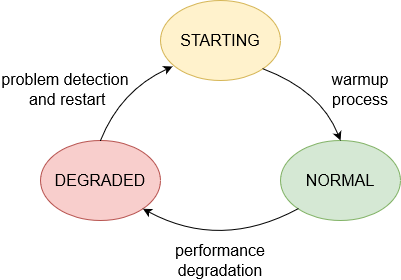
This is not healthy, and does not lead to application performance that is satisfactory and stable – the application only performs as intended while in the green normal state. Moreover, if we rely on automatic restarts whenever we run into trouble, we will not learn much about what conditions cause problems for our applications.
It would be better if we could avoid allocating all the available sockets or injecting too many threads to begin with. Such behaviors are often symptoms of something that is wrong with our design or our understanding of the platform we’re using, something we can fix to increase robustness. In the case of an external HTTP call, maybe we could time out quickly and offer a default value in case of failure, instead of waiting for a long time, or maybe we need to reuse TCP connections for HTTP. We do not necessarily know the appropriate measures for our particular application until we have run some experiments and observed what happens.
Injecting errors without resetting state
There are several ways we can inject errors in our applications without resetting the state. These include:
- Manipulating the network. If we control the network, we can inject errors in the network.
- Adding latency to the dependencies. If we control the dependencies, we can add errors in those. If we do not control the dependency directly, we can inject a proxy which adds errors.
- Simulating errors in the application itself.
We use varieties of all these approaches at NRK. For testing mobile applications on poor networks, the first approach is often used. We also have experience with the second approach, e.g. in testing how client applications respond when we inject latency and errors in a proxy in front of APIs. For testing backend services and APIs, however, we have often used the third approach. One benefit of this approach is that the simulated errors and the resiliency mechanisms exist in the same codebase. This can make it easier to reason about the types of errors we simulate and the approach we use to deal with them.
Typically we introduce latency and errors in the application to demonstrate that we can recover from transient errors and maintain service-level objectives (SLOs) for a service. Ideally we would like to be able to deliver on SLOs during less severe transient errors by timing out, retrying or falling back to a stale cache or default values. Sometimes, if errors are more severe and last longer, we can no longer deliver the required service, but we would like to resume normal operation as soon as possible when the transient errors pass. Put another way, we try to spend as little from our downtime budget as possible when transient errors occur.
We use k6 to load test our applications during these simulated error situations. That way we get a better understanding of how our application operates under various kinds of stress, and can build confidence that our resiliency measures work as intended.
A practical example
One of our APIs handles playback of linear TV channels. As you can imagine, playback is tremendously important for a TV streaming service. If the user can’t watch TV, nothing else matters much. So we have a pretty strict SLO for that API, and need to be able to verify that the API meets that SLO in the face of transient errors.
One of the external dependencies for the linear channel playback API is a list of channels. The list may change, but it changes fairly rarely. This makes it cacheable, which is good for resiliency.
Fetching the list of channels involves an HTTP call, and there are two bad things that may happen with that call: it may fail, and it may take a long time to respond. Since bad things rarely happen in isolation, it is prone to do both at the same time.
To run an experiment on how our application handles problems with this dependency, we need to be able to inject both failures and latency. We simulate transient errors in our web applications using Simmy, a fault-injection library for .NET. It works very well with Polly, which is the library we use in .NET for resiliency-mechanisms such as timeouts, retries and circuit-breakers.
The code shows how we compose our Simmy policy. For faults, we throw an exception with the configured injection rate. Similarly, we introduce the configured latency with the configured injection rate. All of these can vary independently. This gives us the opportunity to create many different failure scenarios for our application.
Since we want to emulate transient errors, we need some way to dynamically control the fault and latency configurations. We use Unleash for feature toggles in our API, so it was an easy solution for us to use feature toggles to switch on and off various configurations. This way, we can see how the application responds to load during various error scenarios, and we can turn the errors off and see if the application will perform as expected again. We can also check to see if it scales out automatically when it starts struggling to respond to traffic or if nodes are restarted.
For each Simmy configuration we want to be available for our experiments, we create a corresponding feature toggle in Unleash. In the Unleash UI, our feature toggles for fault injection look like this:
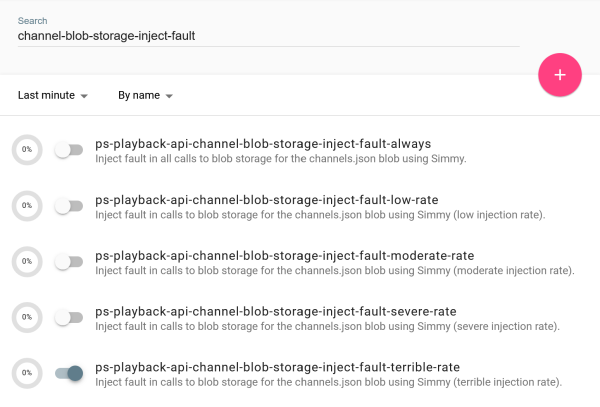
In the code, the feature toggles determine which configuration we choose. More severe configurations take precedence over more benign configurations.
In essence we use Unleash as a poor man’s dynamic configuration system. Each feature toggle corresponds to a hard-coded injection rate. This might seem restrictive, but we don’t really need full flexibility in setting values for injection rate and latency. The few hard-coded alternatives we have defined are more than sufficient to run our experiments.
Results from an early experiment
Before we added resiliency mechanisms to the API, we ran experiments in our pre-production environment with injection of errors. The image below is taken from one of our experiments.
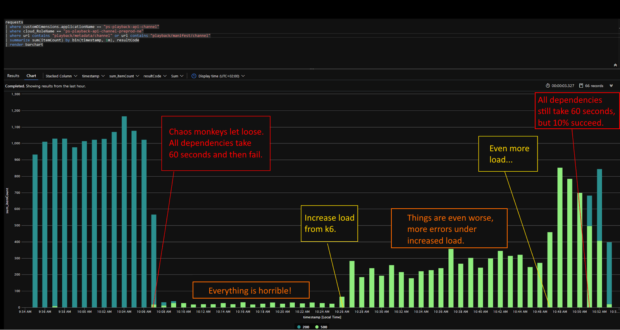
The blue bars are 200 OK and the green 500 Internal Server Error as seen from the application. Because of the added latency, we can see both throughput and correctness taking a hit. We can see that as we add more load, the application will only respond with more errors.
Interestingly, we observe that as low a success rate as 10% yields much better results – the application is able to recover. This is due to the high cacheability of the dependency: channel configuration changes infrequently. Hence we can cache the successful response, and the API is able to respond with 200 OK.
However, this also motivated us to come up with a solution that would be resilient even when the failure rate was 100%. We implemented a solution that allows the API to function completely normally under such circumstances – the only caveat being that changes to the channel list would not be visible. Using Unleash to toggle Simmy errors back in, we could demonstrate that our solution worked as expected in larger scale tests and feel confident that the API would meet its SLO even when the dependency was completely dead.
An important lesson learned from running these experiments is that it is absolutely crucial to re-run the experiment to verify that the resiliency measures actually work. They never do at the first attempt.
To learn more about our ongoing resiliency work at NRK TV, check out Utviklerpodden’s interview with Bjørn Einar Bjartnes (in Norwegian).