
Tl;dr; In the previous blog-posts I have argued for a functional decomposition strategy. Now I will look at an example of how not partitioning by functionality, but rather by entities, has lead to a rapid growth in complexity in our API.
As I discussed in my previous post, our philosophy for new API endpoints is to not have a central concept of a program. A program exists only as the sum of its representation in different contexts. For example, a program on the front-page is only linked to its representation in a series page through a HAL-link to another resource. To play the program from the front-page one must navigate a link to the playback context. The system is partitioned by functionality first.
When I argued for dividing by functionality I simply stated “We attempt to split the application into bounded contexts to better handle complexity” and assumed the reader would accept this as the correct strategy. The inspiration for this strategy is taken from Domain Driven Design, and this specific composition strategy is well described in this presentation by Sebastian Verheuge from JavaZone 2016. Now – however – we will look what happens if we take the route of the entities.
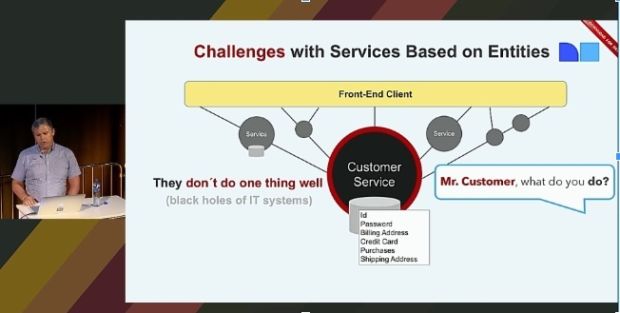
We could easily turn the functionality-first strategy in its head and model by entity first. Imagine there is an endpoint for the entity program that contains all information about a program required for all the functionality we intend to provide for a program. This would be modelling by entities.
Let us travel to the land of nouns
Join me on a journey to the land of nouns, where the entity is the central piece in all modelling. First, we must find the entities to focus on. We are a TV and Radio service, we show TV and Radio programs to users. The program seems like a natural entity.
But, Mr. Program, what do you do?
Now, what does a program really do? A user can play a program. We need a program page to show the user information about the program. We need to display programs on the frontpage. And we must track if a user has seen parts of or the entire program. It is easy to start out with focusing on nouns. When new requirements show up, we can bolt new functionality on the program. Sure, the complexity grows. But how bad is it really, in practice. Let us be pragmatic about it. A program surely can’t be that complex?
Luckily, at least in the context of writing this blogpost, we have this program endpoint already. It has been in production for a number of years, and accumulated functionality over the years. Instead of speculating on the complexity, we can have a look and judge for ourselves.
We can start with the Swagger docs. It is pretty obvious that this endpoint does quite a few different things.

It is not trivial to sort the different aspects of a program into its functional domains. Especially after they have been mixed up in the entity, as they tend to do. It takes time and effort to start to identify the different functionality and identify new, and hopefully more useful, functional contexts. If we read the documentation carefully, we we find UserData, which we could argue belongs in the personalization domain. We find MediaAssetsOnDemand, which has to do with the location of the manifests for playback. There is a plugTitle, which is used in the context of editorial lists or the front-page. Everything you would ever need to do that has to with the program is in this list, but the functional contexts are not clear. Because the contexts have grown into eachother even a trained eye will struggle to separate the functional contexts. Does property X belong in context A,B,C or D? Or in a combination – or maybe all of them?

So, summing up we have one entity – the program – that contains playback, desking, catalog metadata such as titles and images and personalized information. This might, or might not be a problem. The hypothesis was that covering all functional contexts it will, over time, grow too large to handle and this is exactly what we have seen happening in practice.
Example 1 – Playback
We introduced multi-CDN functionality with a third-party service that finds the optimal CDN for the end-user when streaming. The complexity in playback has led to a new endpoint that deals with the playback context. The remaining functionality related to now legacy-playback functionality in the program-endpoint is therefore deprecated. However, as it is mixed up in the program-endpoint it is hard to verify if it still is in use by some clients and therefore difficult to get rid of. Clients might for example not use the URL directly, but they might check that it is there and derive information from the fact that there is a playback URL available.
Example 2 – Personalization
A few years ago, we started tracking logged in user’s progress and favorite programs. This information was also added to the program-entity. Before this change, the program entity was cacheable for all users. A few parameters related to tracking progress for user invalidated the cache of the entire resource. Aspects such as caching and security typically differs across functionality, and by choosing the least common denominator for the entire entity we end up with having to implement high security and poor cacheability for the entire resource.
Confusion
One of our main issues lately with the entity-focus is that it affects the mindset of the entire organization. For example, we do not have a clear mental model that separates the catalogue of content from the playback context. A program might have a version with a audio descriptive audio track for primarily for blind and visually impaired. This is, in our functionally divided model, a problem that belongs in the playback domain. However, we did not separate the playback context from the catalogue context. When audio descriptive audio was introduced, because there was no pure playback context to embed it in, it was introduced as entities in the catalogue as a new entity: https://tv.nrk.no/program/MDRI20000115SYNS/den-som-vil-det-mest. Now we have two entities in the catalogue (https://tv.nrk.no/program/MDRI20000115/den-som-vil-det-mest) of what is really one program in the catalogue context. The playback complexity thus leaks into all other contexts. What is really a different entity only in a playback context now affects all contexts, causing major confusion in a recommendation and personalization contexts as well. For example, if you have seen the audio descriptive program you have also seen the entity without audio description. This complexity is now something the personalization functionality needs to deal with.
In retrospect, it seems pretty clear to everyone involved and that know the domain which of the two strategies can withstand change with the least growth in complexity. However, we must not be tricked to thinking that discovering and designing these subdomains is easy. The reward is great, however, so we should always push for finding new perspectives.
Alan Kay said “Perspective is worth 80 IQ points.” The ability to change perspective and see a concept from only one perspective at a time is a very powerful one – and the opposite – being stuck in a single entity-driven perspective can be a very limiting one.
Conclusion
I hope to have made a case that splitting by entity, even though it is easy in the beginning of a project, is a dangerous path. In any case, the famous rant from 2006 never gets old. https://steve-yegge.blogspot.no/2006/03/execution-in-kingdom-of-nouns.html
Anyway, this API endpoint is now legacy endpoint. It is still in use, but we have moved to the joyful land of verbs.