
24. april tok vi i bruk algoritme-drevne anbefalinger på web-versjonen av NRK TV. Det har allerede gitt gode resultater.
Om du scroller til bunnen av en programside vil du finne et knippe forslag til programmer å se. Listene var tidligere redaksjonelt satt sammen, men nå er det vår rykende ferske anbefalingsmotor som plukker ut programmene fra vårt enorme programarkiv.
Redaksjonen har ikke kapasitet til å plukke ut program-anbefalinger for hvert program, så tidligere brukte vi kategori-lister som anbefalinger. Under alle dokumentarer fant du lenker til de samme dokumentarene. Under alle underholdningsprogrammer fant du lenker til de samme underholdningsprogrammene. Men fra 24. april var det slutt. Anbefalingsmotoren ble tatt i bruk.
Anbefalingsmotoren fungerer ved å bruke et program som inndata for å finne andre programmer. På jakt etter relevante TV-programmer å anbefale finkjemmer den katalogen etter innhold med lignende bruksmønster og tematikk. Hvordan dette funker i praksis gikk vi nøye igjennom i denne saken fra januar, så fokuset i denne omgang vil være på effekten det har hatt.
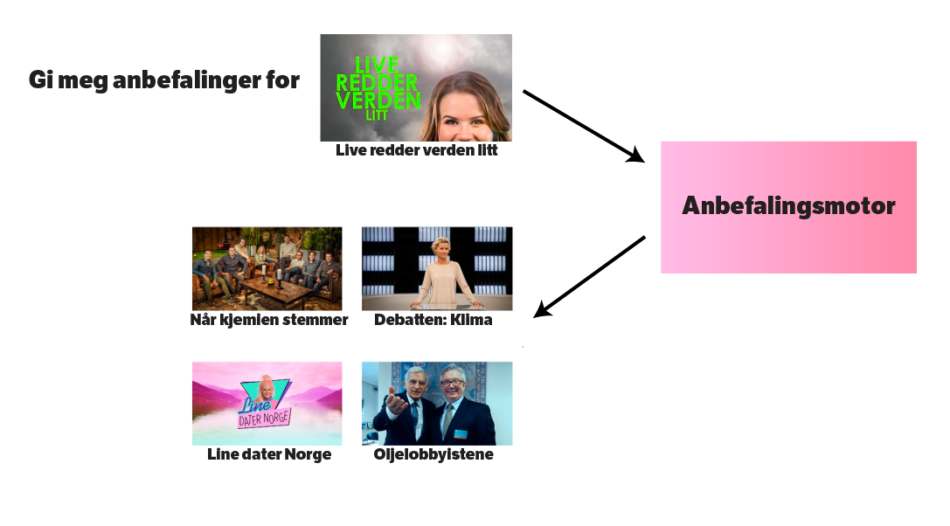
Bevæpnet med møysommelig måling gjennom Google Enchanced Ecommerce har vi fulgt spent med på om vår nye anbefalingsmotor ville føre til større engasjement i listene.
Så hva sier tallene? Virker det?
Det korte svaret er ja. Engasjementet for listene har økt. Folk klikker mer, folk ser i høyere grad ferdig, og de ser mer forskjellig innhold. Men ikke bare ta vårt ord på det, la oss vise deg noen tall.
Klikkrate
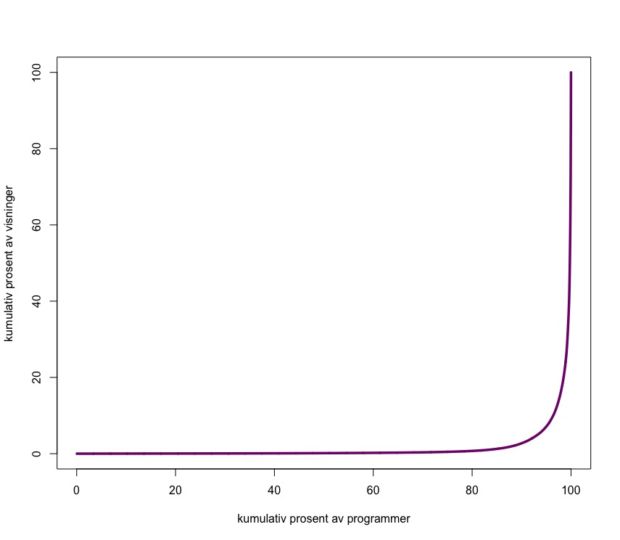
En måte å undersøke om listene skaper mer engasjement er å se på klikkraten. Blir listene klikket på mer enn før? Grafen under viser hvor stor andel av visningene som fører til et klikk:
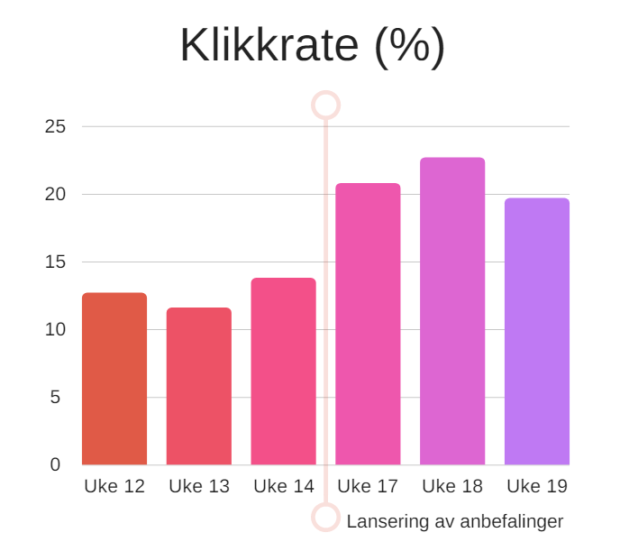
Tallenes tale er klare. De som ser på, klikker mer. Fra å klikke på et program i lista ved ca. 12 % av visningene, klikker seerne nå ca. 20 % av tiden. Dette tilsvarer en solid økning på om lag 66 %. Godkjent!
Vi tolker dette til at vi viser frem mer spennende innhold. Programmene som blir anbefalt er i høyere grad relevante. Men klikk er ikke nok. Vi ønsker at folk skal se TV-programmene de klikker på.
(Merk at uke 15 og 16 er fjernet fra alle figurer i denne saken. Vi lanserte i uke 16, så tallene ville inneholdt data fra både før og etter lansering. I uke 15 hadde vi trøbbel med målekoden, så målingene ble ubrukelige).
Fullføringsgrad
Som lisensfinansiert allmennkringkaster har ikke et klikk på en anbefaling noen egenverdi. Vi har ingen annonsevisninger å maksimere. Det viktige for oss er at vi gir publikum godt og variert innhold. For oss som bygger tjenestene kan vi ikke i så stor grad påvirke selve innholdet, så da handler det om å sørge for at seerne våre finner det innholdet som passer for dem.
For å forsøke å måle dette har vi definert fullføringsgrad. Fullføringsgraden er prosentandelen av visningene av en anbefalingsliste som fører til klikk på en anbefaling, start av programmet, og fullføring av programmet. Alle stegene må fullføres for å gi utslag på fullføringsgraden. Slik har fullføringsgraden utviklet seg etter at vi gikk live med anbefalingsmotoren:
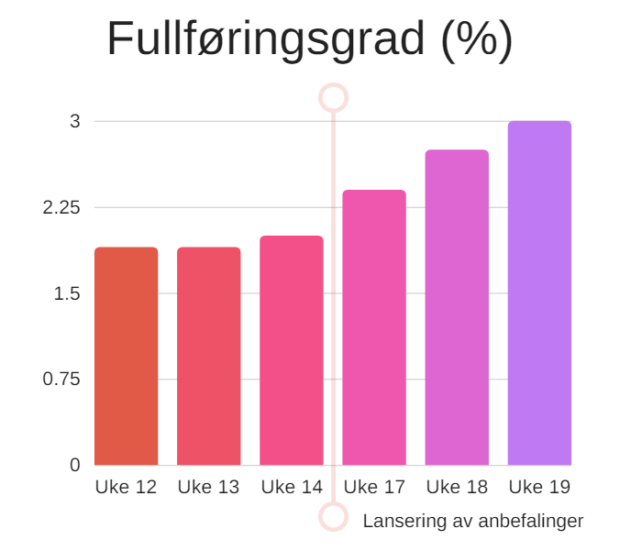
Økningen for fullføringsgraden ser ikke like markant ut som for klikkraten, men den er fortsatt stor. At vi har forbedret fullføringsgraden med ~1 prosentpoeng tilsvarer faktisk en økning på ~58 %. Seerne våre ser oftere ferdig programmer fra en anbefalingsliste etter at de ble algoritme-drevne.
Spredning i anbefalinger
Vi vet at NRK TV har mye godt innhold som ikke blir sett. Katalogen har for lengst runda 100.000 programmer, men svært få av disse blir eksponert til seeren fra dag til dag. En av motivasjonsfaktorene for å bygge en anbefalingsmotor var å få vise frem en større del av katalogen slik at folk skulle oppdage innhold de ikke visste de ville se.
Men hvor mye mer innhold kan vi vise frem med en anbefalingsmotor kontra redaksjonelle lister? Grafen under viser hvor mye unikt innhold som blir anbefalt, klikket på og fullført som følge av en anbefaling.
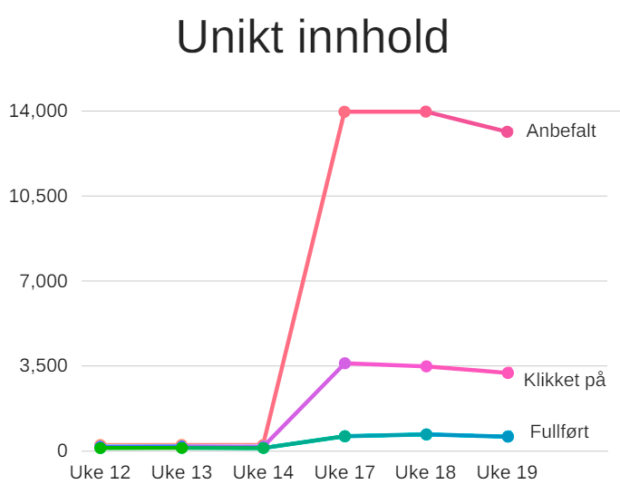
Veksten er eksepsjonell. Fra å anbefale rundt 230 unike programmer daglig, eksponerer vi nå opp mot 14.000 unike programmer til seerne våre per dag. Det er en betydelig del av katalogen som nå blir dratt frem i lyset for første gang.
Av disse 14.000 anbefalte programmene blir hele 3500 klikket på. Vi tolker det som at anbefalingene vi presenterer er relevante. Ikke bare klikker de som ser på mer enn før, men de klikker også på mer variert innhold.
Folk oppdager nye ting!
Før lansering ble ca. 100 unike programmer fullført etter et klikk i en anbefalingsliste. Nå er det rundt 600 unike programmer som blir fullført daglig. Vi har altså fått til noe av det vi ønsket, å vise frem innhold vi vet publikum ønsker å se, men som de ikke vet hvor de finner.
Hva nå?
Vi er ikke på langt nær ferdige. I høst kommer vi til å utvide eksperimenteringen med dette i NRK, og styrker derfor anbefalings-teamet som jobber med dette (søknadsfrist neste søndag!).
Neste steg for NRK TV er å få ut algoritme-drevne anbefalinger på flere plattformer. Android-appen er førstemann ut, så følger vi på med Apple TV. I dag er anbefalingslista gjemt ganske langt ned på program-siden, men den vil nok få en mer prominent plassering nå som vi er trygge på at den fungerer bra.
En ting vi nå virkelig ønsker å få på plass er A/B-testing av forskjellige anbefalingsmodeller. Med A/B-testing kan vi justere på algoritmene og sette dem opp mot den gamle versjonen i sanntid, samtidig som vi unngår sesong- (ukedag vs. helg, sommer vs. vinter) og innholdsmessige (en ny episode av Skam har alltid stor effekt på alt vi måler i tjenesten) svingninger.
Her kan du lese mer om hvordan algoritmene fungerer.
Første, men høyst irrasjonelle, reaksjon: Heller ikke her, hvor ingen jakter etter profitt, skal vi bli spart for sleipe markedsførings-triks for å ta kontroll over sjela mi. (Og som regel lommeboka mi, men det gjelder vel ikke her.)
Jeg burde klare undertrykke den følelsen jeg ofte har i nettbutikker som kommer med tilsvarende anbefalinger, at de invaderer privatlivet mitt. De kunne gjerne sendt meg til psykoanalyse, om behandlerens rapport hadde hjulpet dem til å ta enda mer kontroll over mine interesser og min lommebok. Når jeg ser hvor ofte f.eks. Amazon treffer i sine anbefalinger, får jeg en følelse av å være Amazons lille marionett.
Og jeg føler meg tråkket på når de bommer… Amazon begynte brått å anbefale meg masse homse-film. Jeg har venner som er homser, og det er helt OK; jeg bryr meg filla om hvem de deler seng med, det er en privatsak. Jeg har ikke noe imot homsefilmer heller, men jeg blar forbi dem. Så hvordan fikk Amazon den ideen at jeg ville ha masse slike tilbud?
Jeg tror jeg fant forklaringen: Jeg kjøpte en bunke filmer, og det tok måneder før jeg kom til en 1960-talls italiensk kunst-film i svart-hvitt, en smått surrealistisk historie basert på gammel mytologi. Halv-guder er jo gjerne både sterke og vakre, og i gammel mytologi respekteres ikke alltid moderne amerikanske kleskoder fullt ut; det hendte at halvgudene verken hadde Levis eller Nike på kroppen. Det er helt naturlig (bokstavelig talt). Da jeg så filmen, slo det meg overhodet ikke at det var noen slags «homse-film» bare fordi vi så en naken mannskropp. Men det mente visst Amazon at det var.
Her i landet gjør det ingenting om folk får vite at jeg får masse anbefalinger av homse-film, men i en del miljøer i USA, kjent som frihetens høyborg, kan det være svært negativt for ditt omdømme, både privat og jobbmessig, om det skulle komme ut at du har «slike tendenser».
Hvis filteret gir meg for ferdigtygget mat, for (semi-)endelige beslutninger om hva jeg ‘selvfølgelig’ må være interessert i, da vil jeg mistrives med det. Det skal stadig vekk være meg selv som søker og velger, jeg vi gjerne ha hjelp i søke-prosessen, men får jeg presentert en meny der jeg kan velge mellom Coke, Pepsi, Gran Cola og IsiCola, da skriker jeg NEI! Jeg vil ha nypresset rå blåbærsaft! Eller Lapsang Suchong te!
For å gi konkret feedback: En av de aller enkleste måter jeg kan styre valget på er om jeg kan sette opp preferanser for å undertrykke, eller nedprioritere, etter ulike egenskaper. Kutt ut alt som er merket ‘Sport’. Alt som er merket ‘Førskole’ eller ‘Barneskole’, og trekk det som er merket ‘Ungdom’ ned til halv verdi (på relevant akse – evt. doble verdien dersom lav verdi betyr ‘kort avstand, svært interessant’). La meg få fjerne (eller velge ut) treff produsert, eller sist vist, innen et tidsintervall.
Jeg får inntrykk av at det krever en del prosessorkraft å bygge opp dette nettverket av slektskap mellom innslag; du kan ikke gjøre det fra grunnen av for hvert eneste søk. Men for hvert enkelt søk kan man ta en forhåndsgenerert, felles liste over nære alternativer, og vekte f.eks. de første hundre innslagene – flytte nedover i lista de som brukeren har indikert mindre interesse for. Det er fullt realistisk å gjøre for hvert enkelt søk.
Takk for en lang og velbegrunnet tirade, selv om jeg ikke føler at vi er de riktige å rette skytset mot… ennå. Anbefalingene vi presenterer i dag er nemlig ikke personaliserte, så du skal slippe å få trekt dine «homse-film-tendenser» (sic!) frem i lyset hos oss.
Som beskrevet i artikkelen gjøres alle anbefalinger i kontekst av et tv-program, og ditt (anonymiserte) bruksmønster er kun brukt til å lage «andre som så dette, så også dette»-modellen. Så foreløpig er du trygg hos oss.
Poengene du tar opp er alikevel viktige. Vi vil bevege oss i en retning der anbefalingene blir personaliserte, og da vil vi støte på problemstillingene du skisserer. Det enkleste svaret jeg kan gi deg er at vi ikke ønsker å personalisere tjenesten for publikum som ikke er innlogget, og vi vil aldri kreve innlogging. Dermed vil du alltid ha et valg på om du vil ha personaliserte anbefalinger eller ikke.
Videre kan det godt hende vi bygger inn et aktivt valg i tjenesten. En av-på radiobutton i profil-innstillingene er kanskje alt som skal til for å blidgjøre andre som får fnatt av «sleipe markedsføringstriks?»
Det konkrekte forslaget ditt rundt å påvirke anbefalingene direkte er ting vi diskuterer. Det er to ting som taler i mot: 1. Det høres ut som et UI-mareritt å designe på en brukervennlig måte. 2. Når brukere etterspør denne typen funksjonalitet (det er det ikke mange brukere som gjør), ender de opp svært sjelden opp med å bruke den. Kanskje nettopp fordi det er vanskelig å kommunisere hva og hvordan man påvirker listene, og UI-et er dårlig?
Det siste du skisserer, om måten det fungerer på, er faktisk måten vi håndterer håndheving av forskjellig regler i dag. Så om vi hadde dine bruker-preferansener hadde vi nok gjort det på akkurat den måten 🙂
> «Videre kan det godt hende vi bygger inn et aktivt valg i tjenesten. »
Ja for all del la folk bruke kategori- og sub-kategori som dimensjoner i et personalisert filter. Dette vil hjelpe folk unngå noen typer innhold og finne frem til det de ser etter, eller foretrekker. Å la de prioritere er også fint om dere klarer det.
Anbefalningsmotoren har nemlig også ansvar som søkemotoren å hjelpe deg finne det du ser etter.
Da kan man f.eks ekskludere kombinasjoner som
– Film > Drama
Likeså burde man kunne definere hvilke kombinasjoner du vil ha i ditt eget filter, som f.eks
– Film > Komedie
– Dokumentar > Politikk
– Dokumentar > Verden
– Sport > fotball
– Sport > hockey
I den ideelle verden kunne man også rangert dette og laget en «feed» på epost eller noe. Eventuelt en huskeliste med ting man vil se på, spesielt for TV-serier.
I januar-artikkelen det linkes til blir det fortalt at programmer lokaliseres i et 20-dimensjonalt rom for å bestemme nærhet.
Er det mulig å gi en grei og forståelig oversikt over hva disse 20 ulike aksene representerer av egenskaper ved programmene?
Det korte svaret er nei. Det lange svaret følger under:
De 20 dimensjonene er en redusert representasjon av
matrisen som inneholder «alle brukere som rader, alle programmer som kolonner, og alle visninger som en verdi».
Se for deg denne matrisen (i.imgur.com/bmW79NS.png) med alle programmene våre og alle brukere som har sett mer enn 5 programmer. Programmer de har sett får verdien 1. Programmer de ikke har sett får verdien 0. Den er svær! Og den har vanvittig mange 0-er. Vi sier at det er et «sparse matrix.»
Deretter bruker vi en algoritme, ALS (quora.com/What-is-the-Alternating-Least-Squares-method-in-recommendation-systems), til å faktorisere denne matrisen til to mindre matriser, der hver vektor i hver av matrisene har 20 faktorer.
De forskjellige faktorene representerer til sammen bruksmønsteret til hvert program, og kan brukes til å finne lignende programmer. Men det er veldig vanskelig å tildele noen eksplisitt mening til hver faktor.
For noen av faktorene kan vi se tendenser. Vi har f.eks. identifisert en «natur»-faktor, der programmer med høye verdier for denne faktoren handler om natur (Monsen, Ut i naturen, osv.) og programmer med lave verdier er noe helt annet. Men for andre faktorer ser vi ikke noe umiddelbart «menneskegjenkjenbart» mønster. Der har datamaskinen tydeligvis sett noe som vi ikke ser…
Hei!
Kjempekult at dere har jobbet med anbefalningsmotorer.
Hvis dere er på vei mot ML-modeller så bør dere se på hvilke modeller AirBnB bruker. De har skrevet om det på bloggen, samt hvordan de automatiserer testing og sammenligner resultat per metode.
medium.com/airbnb-engineering/automated-machine-learning-a-paradigm-shift-that-accelerates-data-scie…
Håper det er gøy. Fint at dere får resultatene inn med Advanced Ecommerce i GA. Artig bruk av den funksjonen.
Hei Tobias.
Ja, jeg leste den artikkelen fra AirBnb. Spennende måte å jobbe på, men det er nok foreløpig litt vel ambisiøst for vårt lille team på 3 stykk. Men rent generelt vil vi nok se på forskjellige ML-modeller fremover.
Gratulerer med launch og gode tall! Håper dere kommer med oppdaterte grafer når A/B-test er på plass 🙂
[…] Les også: Hvor godt virker algoritme-drevne anbefalinger i NRK-TV? (NRKBeta) […]
[…] NRKs algoritmedrevne anbefalingssuksess […]
Spennende, men som andre har vært innom: Også skummelt. I en tilsvarende post for en tid tilbake problematiserte dere jo dette selv, og så vidt jeg kan huske lovte dere å holde fast på det som gjør at man ikke kommer i et ekkokammer, men hele tiden også blir eksponert for den fulle bredden i NRKs redaksjonelle virksomhet.
For å sette det på spissen: Det å ikke treffe perfekt er en vesentlig del av oppdraget til NRK.
Hvilke tanker har dere om dette nå?
Et opplagt svar vil jo kunne være å dele anbefalingene i to (en grovkornet redaksjonell liste og en finkornet automatisk), eller redaksjonelt overstyre her og der, for å sørge for at de viktige programmene dukker opp hos alle, uavhengig av om de har likt den type sendinger før.
Hei Martin, takk for reflektert innspill. Du er inne på noe vesentlig i hvordan en anbefalingsmotor for NRK skiller seg fra en anbefalingsmotor fra f.eks. Netflix. Vi er gitt et samfunnsoppdrag av Stortinget som innebærer at vi skal informere, opplyse, utfordre og underholde nordmenn flest. Da kan vi ikke skape ekkokammer.
Bra sagt. Vi har formulert det som «å gi seeren noe de ikke visste de ville ha». I tradisjonell lineær-TV er det vanlig å sette opp smalt og viktig innhold i etterkant av noe stort, bredt og populært, i håp om at flere skal få med seg det smale innholdet. Dette er dokumentert til å virke, og kalles lead-in effekten (medienorge.uib.no/files/Eksterne_pub/NRK_Oslo-Economics_rapport-2014_20.pdf). Vi må finne ut hva som kan være «lead-in effekten» i strømmealderen, uten å være formanende.
Redaksjonen vår er veldig viktig for oss, og den vil ikke forsvinne selv om vi nå har algoritmebestemte anbefalinger. Jeg vil si at kunnskapen og kompetansen deres er et av våre fortrinn. Et av de store spørsmålene vi må svare på er hvordan vi best kan kombinere automatiske og redaksjonelle anbefalinger.
En av tingene vi skal implementere før sommeren er å kunne overstyre de automatiske anbefalingene på program-nivå for å kunne pushe viktige premierer. Altså at vi kan si at «første anbefaling for Skam SKAL være XYZ».
Det er godt å se at dere fortsatt er bevisst på dette. Bra!
Min første posting står mellom to postinger som er postet tidligere på dagen.
I tillegg synes jeg det er vanskelig å forstå hvem som svarer hvem, eller om de svarer på artikkelen.
[…] NRK’s algorithm-driven recommendation success […]
[…] Dagens anbefalinger på NRK TV er algoritmestyrte, og baserer seg på publikums samlede bruksmønster og innholdsanalyse. Vi har i tidligere artikler på NRKbeta fortalt om hvordan vi bruker algoritmene for å anbefale innhold og om hvor godt de faktisk virker. […]