Det er forskjell på å kunne søke – og faktisk finne igjen noe. Da jeg startet i radioen på 80-tallet var «arkivet» en håndskrevet protokoll hvor du førte inn ferdige program og et digert båndarkiv med 40.000 1/4″-lydbånd. Å finne igjen et program betydde å finne igjen et bånd i et enormt lagerrom.
Krisen var fullkommen hvis noen hadde satt inn båndet feil i arkivet, for eksempel på feil årtusen-serie. Da var det ofte bare en av de eldre tekniske vaktsjefene som hadde nok sjette- og syvende sans til å finne dem igjen. 40 års erfaring hadde vist henne hvilke feil som var de vanligste.
Radioarkivet i dag
I dag er Radioarkivet 790.000 metadataposter i en graph-basert database (OpenLink Virtuoso). Denne inneholder 2,8 PetaByte med lydfiler i et stort serversystem (Dell/EMC Isilon).
Hvordan finner NRK egentlig tilbake til gammelt nyhetsmateriale blant 123.000 Dagsnytt-poster? Eller hvordan finner vi en sak fra Nitimen blant 3000 bevarte enkeltprogrammer? Hvordan finner vi noe som helst blant alt det som blir lagret?
Svaret er gjemt i begrepet metadata.
Metadata er alt vi har skrevet om programmene våre som titler, beskrivende tekst, navn på medvirkende og programledere, opptaks- og sendedato, rettigheter, opphavspersoner, kvalitetsnivå, eller tekniske metadata. Tekniske metadata kan være båndnummer for gamle opptak (NRK38345), lydformat (.mp3) eller sted i verden / kartposisjon (geokoordinater). Og det finnes mange flere…

Origo – en ny begynnelse
ORIGO er et prosjekt som setter struktur på metadata og bygger NRKs logistikk-infrastruktur på nytt fra grunnen av. Planen er å kunne hente ut alle beskrivende metadata om programmene og lagre dem med ny og bedre struktur i et moderne «åpen kildekode»-databasesystem. Prosjektet startet i 2015, og har allerede levert flere nye muligheter for NRKs journalister.
NRK bygger selv brukergrensesnittene som gjør at du kan søke i historien. Radioarkivet gjør det mulig å søke og gjenbruke klipp og programmer fra NRK radios 80 års historie. Potion gjør det mulig å søke og gjenbruke fra NRKs TV-historie.
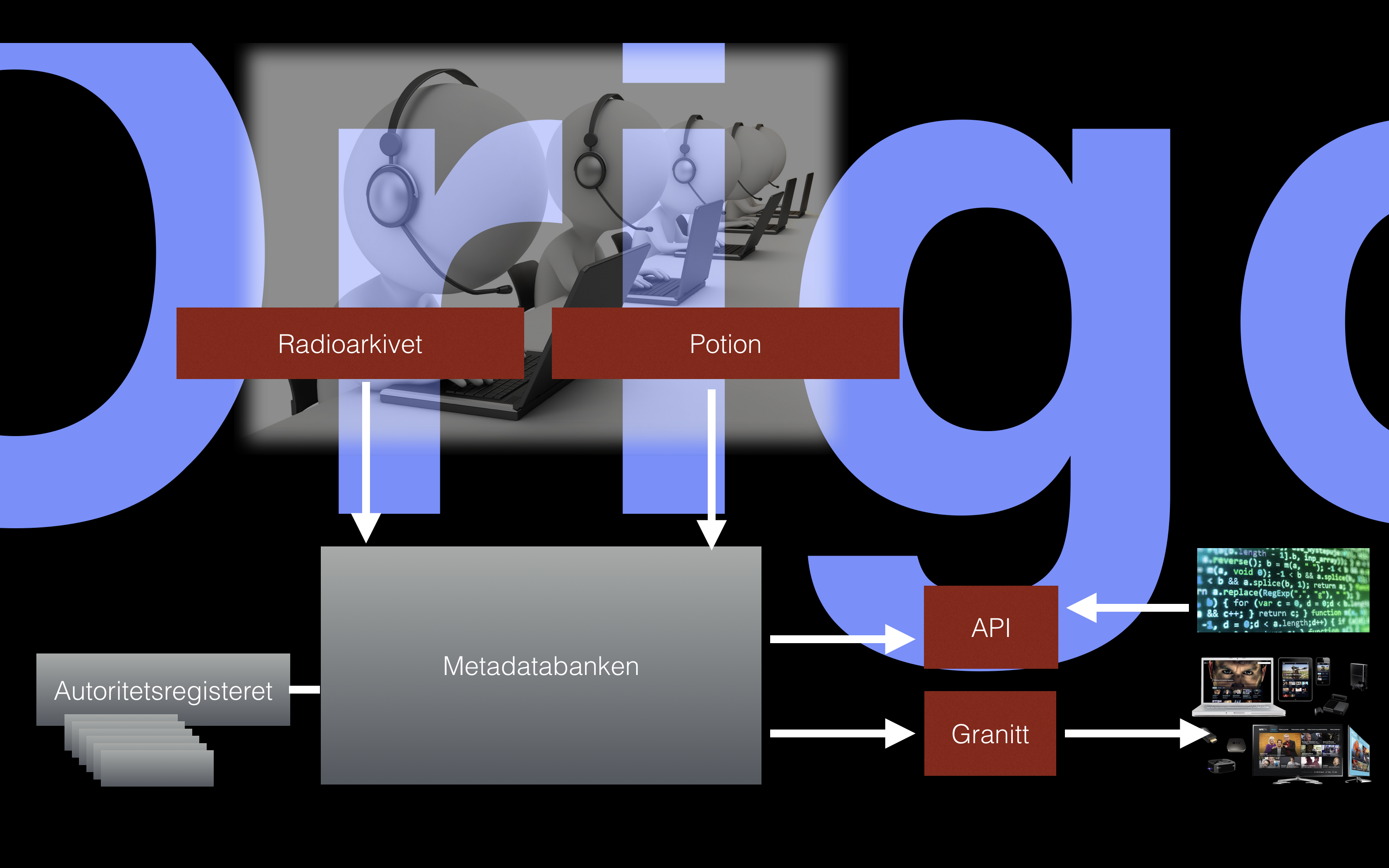
Under grensesnittene ligger en stor database for metadata. Denne er basert på åpen kildekode og lages som en såkalt graf-database. Metadatabanken skal etter hver innholde alle metadata for NRKs programmer – både i radio og TV. Og den er laget for å gjøre det enklere å finne og for å kunne bruke hele eller deler av programmene på nytt. De kan brukes til å lage nye programmer. Og de kan brukes som deler av artikler på nrk.no. Målet er at det til slutt skal bli mye enklere å publisere programmene på nett, mobil eller sosiale medier.
Leting etter et 30 år gamle klipp
Å lete opp et gammelt klipp fra arkivet er av og til som å lete etter en nål i en høystakk. NRKbeta skrev i 2015 om hvordan vi kunne bruke gamle stillbilder for å se utviklingen av sidearmene til Jostedalsbreen.
Når jeg leste denne artikkelen slo det meg at «dette hørtes kjent ut». I 1986 var jeg blodfersk programingeniør i fjernsynets ENG-gruppe. ENG står for Electronic News Gathering. Dette er den tekniske gruppen bak produksjonen av NRKs nyhetsinnslag.
En morgen fikk jeg beskjed fra vaktsjef å henge meg med fotograf Liv Benkow på en jobb i Jotunheimen. Breen hadde «kalvet» et par biter på størrelse med «Oslo rådhus» og tatt med seg flere turister i raset. Folk var skadet og drept.
Vi ble sendt opp til Jotunheimen dagen etter for å snakke med vitner, politi og overlevende.
Med sjøfly, bil og båt bar det opp til Jotunheimen så raskt det var mulig. Opptak ble gjort, og så var det samme veien tilbake til NRK på Marienlyst. Innslaget ble så vidt klart til sending fem minutter før det skulle på sending kl. 19:30.
Men hvor var dette klippet nå?

Leting etter nål i høystakk
Vi begynner letingen i SIFT – antagelig ett av Norges eldste dataprogram fortsatt i daglig bruk. SIFT betyr Søking i Fri Tekst. Dette er en fritekst-database laget av Norsk regnesentral i 1979! Og den er fortsatt i daglig bruk i NRK.
Hva var det breen het igjen?
Vi søker på Briksdalsbreen. Det gir ingen treff i 1985-86. Opptaksår (metadata) er jeg sikker på, fordi dette klart var i tiden jeg gikk på NRKs programingeniørkurs. Så en metadata-referanse er jeg sikker på! Men ingen treff i disse årene.
Hvordan kommer vi videre?
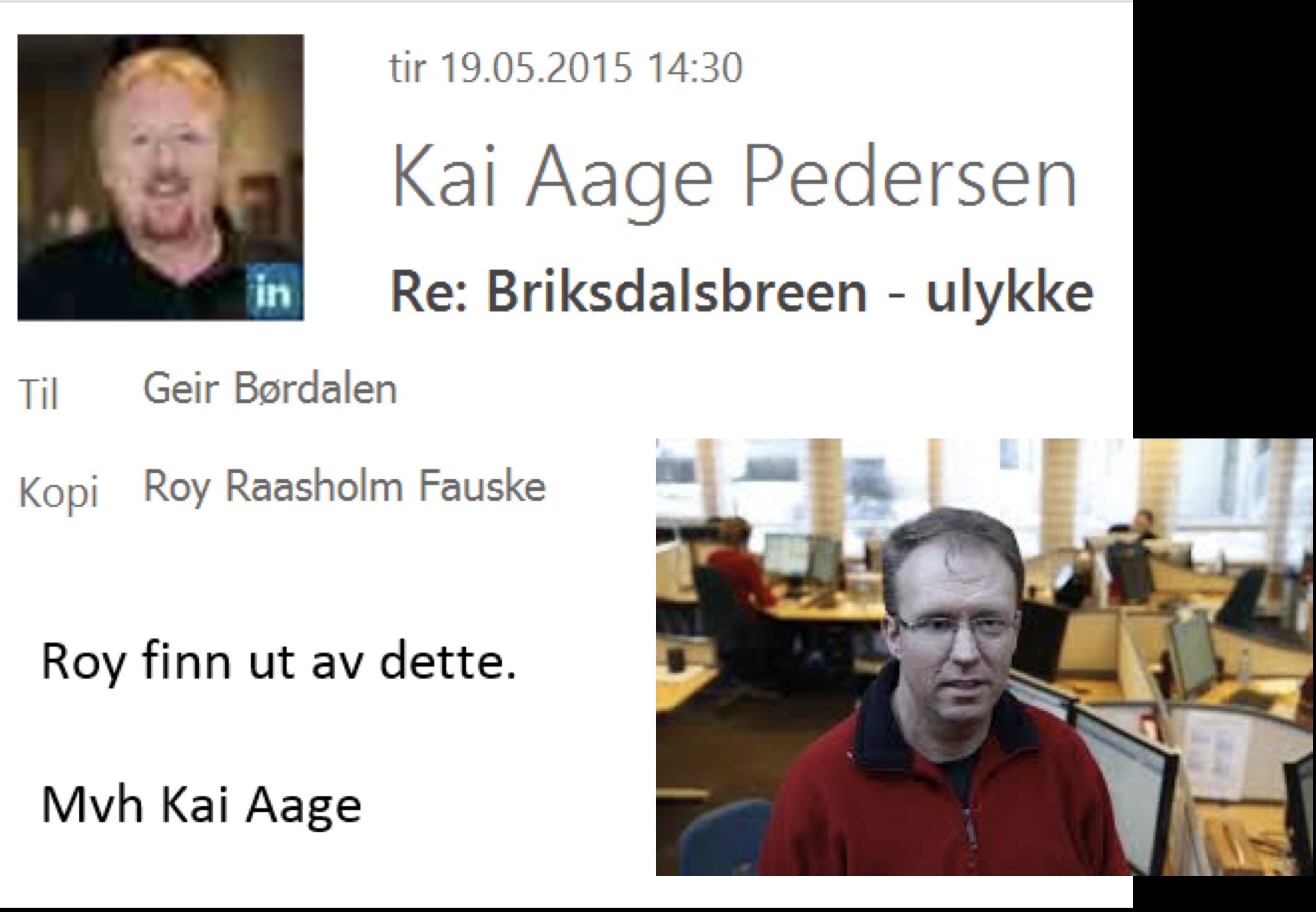
Når NRK-folk og andre journalister ikke vet, da spør vi kjentfolk. De som har vært der før! Vi bruker manns minne, noe som tilfeldigvis også er navnet på Nasjonalbibliotekets hovedrapport. Vi redder oss fortsatt fordi vi har folk som var der da det skjedde.
{kind=link}
Problemet er bare det at de som var der da det skjedde, de husker ikke nøyaktig de heller. Jeg prøver regionsredaktør Kai Aage Pedersen i NRK Sogn og Fjordane. Og han sier: «Roy finn ut av dette», med henvisning til redaksjonssjef Roy Raasholm Fauske på nyhetsdesken.

Mens vi venter prøver jeg selv det vi alle gjør, Google. Vi søker eller googler det. Et Google-treff fører meg tilbake til en av NRKs lokale kunstverk i logistikk – nemlig NRKs fylkesleksikon for Sogn og Fjordane (nå overtatt av firmaet Allkunne).
Dette har bl.a. en meget god oversikt over breulykker i Jotunheimen for de siste 400 årene. Allkunne gir referanser til en breulykke i 1986 – ved Nigardsbreen. Jeg søker etter feil isbre!

Hvorfor tar jeg feil? Jo, fordi dette er to brearmer av Jostedalsbreen, en på hver sin side av hovedbreen. Og ikke mer forskjellige, enn at jeg ikke klarer å skille dem. Tilbake i SIFT får jeg et treff på breulykke ved Nigardsbreen i 1986.
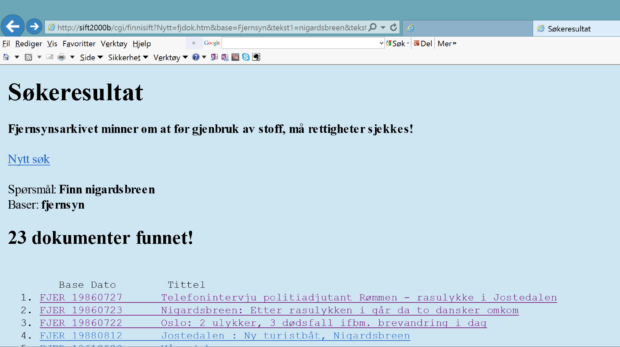
Metadataene viser et innslag som er bevart: Telefonintervju politiadjutant Rømmen – rasulykke i Jostedalen. Men i SIFT er det ikke mulig å se påsyn av bildene. Da må vi ta i bruk et annet system. I Programbanken kan vi så med et tilsvarende søk finne klippet under:
Jeg tror letingen tok 2-3 timer. Ikke akkurat optimalt for en rask produksjon i dagens verden. Og i overkant i tidsbruk til at desken gidder å hente ting fra arkivene.
I erfaringene fra dette, så vi tydelig at vi trengte noe bedre i bunn av logistikken til NRK for å bli raskere og bedre.

Automagisk
Det var redaksjonssjef Tone Donald i P3 som klarte å sette navn på visjonen for Origo. Bygg det «automagisk», sa hun i et av de første møtene vi hadde med ledergruppa til Marienlyst-divisjonen. Bygg det så vi ikke merker at det er der. Bygg det slik at vi slipper å tenke på det. Bygg det slik at det går av seg selv.
Automagical
«…referring to complex technical processes hidden from the view of users or operators, resulting in tech that just works.»
Origo-visjonen er et ønske om å gjøre ting raskere, enklere, tilgjengelig for alle, modul oppbygd, med god og fleksibel arkitektur, effektiv, og automatisk . Men det har likevel vært automagisk som har blitt stående igjen som viktigste visjon.
Programmet som startet magien, Potion
Det automagiske startet med Potion, en egenutviklet programvare for søk, påsyn og send til meg / send til system -funksjonalitet. Potion ble laget slik at den skal fungere både på toppen av gammel systemstruktur og mot de nye Origo-komponentene. På denne måten bygger Potion bro fra gammel til ny infrastruktur i NRK.
Potion gir søk-mulighet inn i alle TV-klipp og programmer, både de som ligger i nåværende produksjonssystem Programbanken og i alle nett-klipp. NRK-arkivene er store. Det er ca 2 mill. klipp eller ca 45 PetaByte lagring, i NRKs lagringssystemer for video. Derfor måtte også det automagiske få en utvidelse i denne retningen.
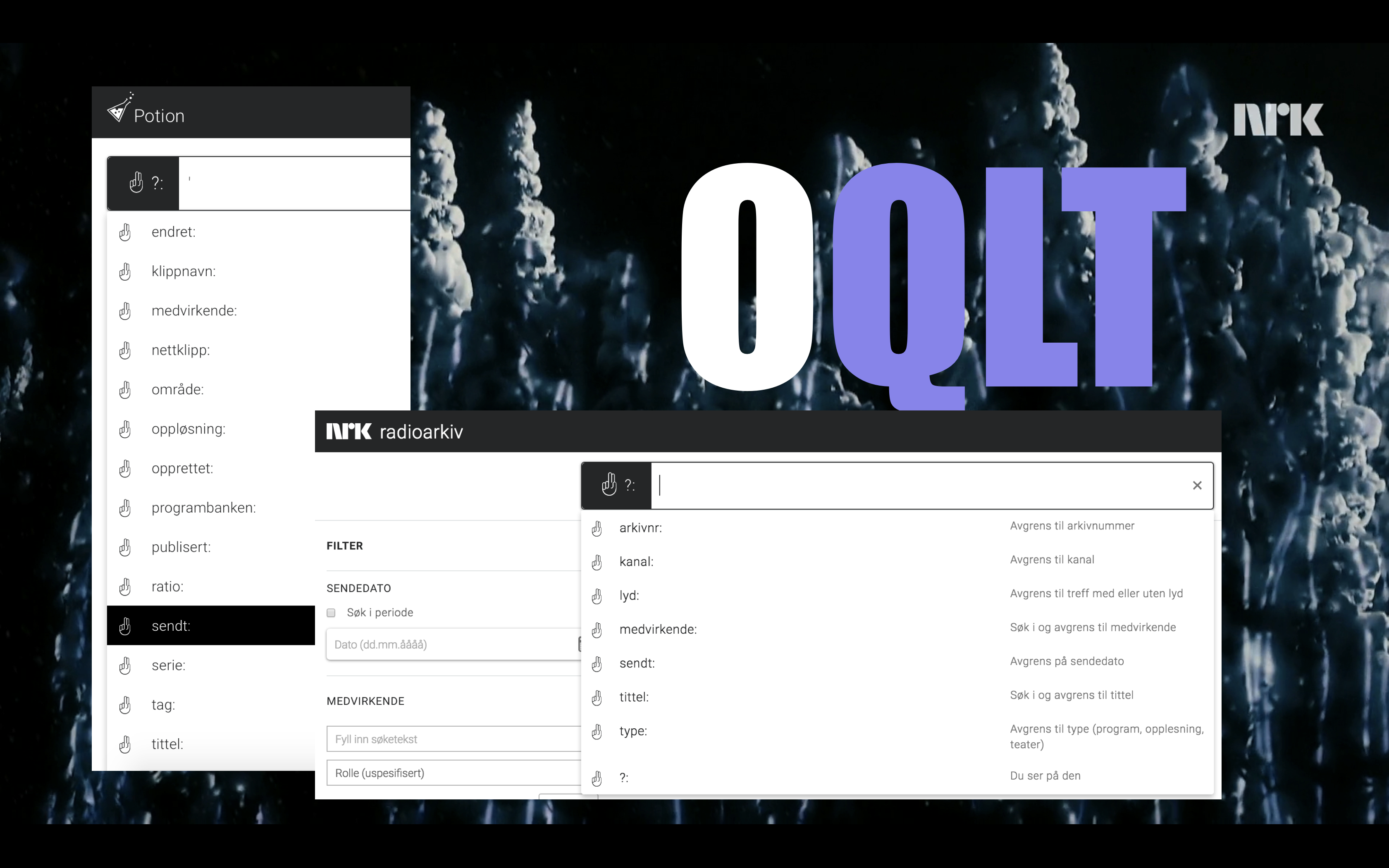
OQLT – det automagiske søket!
Potion var første system som fikk bygget inn Origo-visjonen om:
- et søk like enkelt som Google enlinje
- Finn.no’s venstrekolonne (filtersøk)
- innebygd avansert søk for arkivarer (men skjult for vanlige brukere)
Origo Query Language Toolkit = OQLT (uttalt: okkult).
Det hjelper med god humor innad i utviklingsteamet, og en og annen heavy metal-rocker på plass i staben…
Se video under for å se hvordan et søk etter første episode i «Nobel – fred i vår tid» blir gjort i Potion. Videoen viser også hvordan klipp kan publiseres mot en artikkel i nrk.no.
For meg ble OQLT forskjellen mellom søk, og faktisk det å kunne finne. Klippet fra Nigardsbreen lot seg finne i løpet av 20 sekunder. Jeg finner nå f.eks. gamle Nobel-konsertklipp i løpet av kort tid. Og klipp av Dollie (før de het delux) blir funnet på få minutter. Mange av disse ville ha krevd et dyptdykk i NRK-arkivet sammen med arkivarer med 30 års erfaring – og god tid. Noe vi sjelden har…
Hvorfor søker jeg på Nigardsbreen – og Nobel – og Dollie?
Jo, selvsagt fordi dette er metoden vi alltid bruker i møte med et stort arkiv. Vi søker på ting vi har vært med på selv, fordi det er vårt lakmuspapir på om det er mulig å finne noe i arkivet. Vi søker på mine ting – og våre ting. Ting vi selv har opplevd. Hvis det lar seg finne, da kan også andre ting la seg finne.
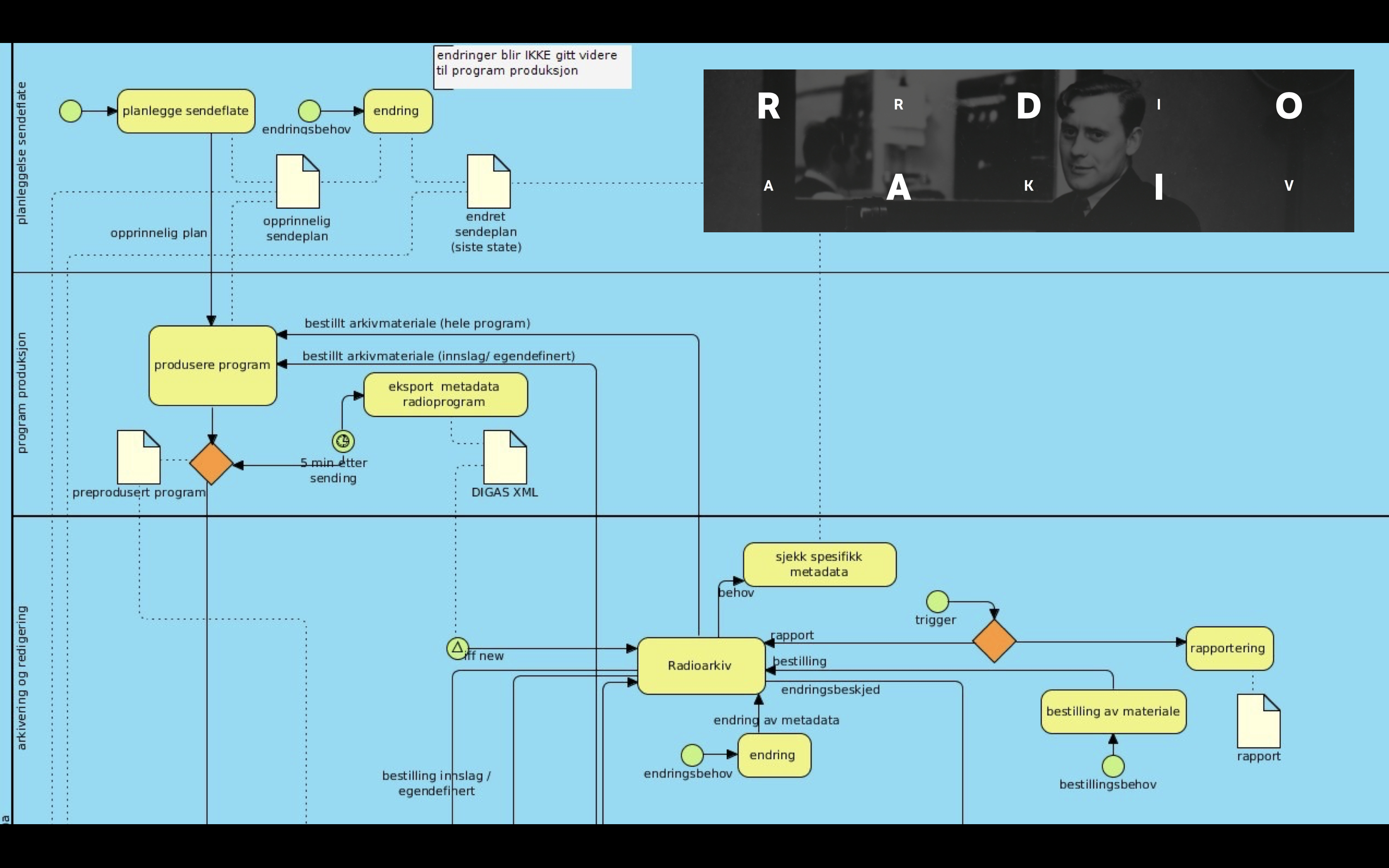
Radioarkivet
Neste Origo-komponent som har fått OQLT innebygd, er Radioarkivet. Radioarkivet er NRKs første byggestein for det vi kaller Metadatabanken. Metadatabanken er tenkt å inneholde (en gang i fremtiden) alle metadata for alle radioprogram, TV-program, klipp, stills, tekstefiler, grafikk og dokumenter som er laget av NRK eller sendt på en av våre plattformer (radio, tv, nett, mobil).

Radiohistorien er dessverre full av hull. Bånd var dyrt, så dermed tok man ikke vare på alt som ble produsert eller sendt. I perioden før 1990-tallet ble det kastet mye av radioens historie. Noe av det som er borte, er egentlig helt krise.
På 1950-tallet var Paul Temple og Radioteateret på høyde med den mest populære krimserie på tv. Siste episode av Paul Temple og Gregory-saken (1952) gikk tilfeldigvis samtidig med en bokselandskamp mellom Norge og Danmark på Jordal Amfi. Arrangørene fikk dispensasjon til å kjøre radiosendingen over høyttaleranlegget i salen i pausen, for å sikre at landskampen kunne gjennomføres uten tomme tribuner… Radioarkivet inneholder dessverre bare episode 1 og 2 (av 10) fra dette hørespillet.
Resten er tapt.
Radioarkivet inneholder alt som er tatt vare på fra radioens historie – og for fremtiden (fra 2013) tar vi vare på ALT. Vi tar vare på opptak av alle radiokanaler og distriktssendinger – og alle masteropptak (program som tas opp før sending), samt råstoff som er «arkivverdig». Alle program tas vare på i full produksjonskvalitet (PCM, 24 bit, 48 kHz samling) og alle webkvaliteter (mp3, AAC, HE-AAC).
Se video under for å se hvordan et søk etter dagens program av Nitimen blir gjort i Radioarkivet. Videoen viser også hvordan Radioarkivet er linket med NRKs musikkarkiv – og hvordan materiale gjenbrukes i Digas (som er Radioens produksjonssystem):
Metadatabanken – moduloppbygd metadatalagring
Metadatabanken er bygget basert på åpen kildekode – og lagring skjer i en såkalt graf-basert database (Openlink Virtuoso tripple store). Hovedbyggesteinene i den såkalte semantiske webben (RDF, OWL, SPARQL) er den del av Metadatabanken. Pr i dag er radio, tv og kortere nett-klipp på plass i løsningen.
Mens musikk, grafikk, stillbilder, teksting og dokumenter er under arbeid eller kommer senere. Planen er at Metadatabanken skal være etablert med alle hoveddeler i 2018.
NRK er ikke alene om å bygge ny infrastruktur med byggesteiner fra semantisk web. Både Statoil, Hafslund, Det Norske Veritas og flere offentlige sektorer har vært aktive med å bygge ny infrastruktur basert på den semantiske weben. Dette gjør også at vi har sett samarbeid mellom sektorer som tidligere ikke normalt hadde med hverandre å gjøre.
Viktig med god arkitektur og forståelse av arbeidsflyt i bunn
Når du bygger infrastruktur som skal vare i mange tiår eller mer, er det viktig å kunne samarbeide om standarder og ha en gjennomtenkt arkitektur i bunnen. Men enda viktigere er det å bygge løsninger som brukerne faktisk kan bruke. Origo-prosjektet har forholdt seg til to brukergrupper – publikum og NRKs egne brukere (journalister, redaksjonelle- og produksjonstekniske medarbeidere). Disse gruppenes arbeidsflyt har hele tiden vært i fokus for å kunne bygge best mulige løsninger.

Forstå og håndtere kompleksitet
En moderne mediebedrift er kompleks – med en mengde forskjellige arbeidsoperasjoner som løses hver eneste dag. Med leveranser til nett- og mobile plattformer har denne kompleksiteten økt dramatisk. NRK har endret seg fra en kringkaster til å bli et nærmere et forlagshus. For at publikum skal kunne finne igjen programmer og kortere klipp trengs struktur for metadata, at gode metadata faktisk blir levert, og programvare for raskt og enkelt å finne tilbake i programmene. Håndtering av denne kompleksiteten har gitt behov for nye automagiske verktøy.
Forstå og håndtere kompleksitet er også regel 7 i Berlin School of Creative Leaderships liste for 10 prinsipper for kreativ ledelse. (David Slocum)
Først og fremst glad for at jeg klarte quizen for å slippe igjennom – dernest; bra artikkel, Geir!
Takk for god tilbakemelding, Thomas.
Høres ut som et skikkelig ambisiøst tiltak! Og det virker som dere er bevisst at metatdata og metadata kan være mye rart, av svært vekslende kvalitet.
For historiske opptak er dere på mange måter i lignende situasjon som de som prøver å systematisere metadata om mennesker, eller slektsforskere. Jeg har hatt adgang til å se noen av de historiske nedtegningene i radioarkivet, og kjenner igjen mange elementer: Høyst usikker info (en ‘Hans Hansen’ er ført opp som deltaker i programmet men uten videre info – kanksje han var den den ukjente eventyr-oppleseren?). Info mangler: Sent 13. sfdj 1952 – måneden er uleselig. Tvetydig info: Intervju med fisker Ola fra Senja – spør vi gamle folk, mener den ene at det var Ola Oppibakken, en annen er sikker på at det er Ola Neidbakken. Åpenbart feil data, men det er det eneste vi har: Intervju med Karl Veggimellom fra 1961, men mannen døde i 1959… Osv. osv.
Slektsforskere spiser slike problemer til frokost, lunch og middag. For 20-25 år siden ble det utviklet en «standardmodell» for slektsforskning, «GenTech»-modellen (se ngsgenealogy.org/cs/gentech_projects). En av de virkelig gode sidene ved modellen er hvordan man handterer ulike motstridende kildeopplysninger, kilder av ulik kvalitet og pålitelighet, hvordan alle konklusjoner kan føres tilbake til det utvalget kilder de er basert på, osv. osv. (GenTech-modellen er et virkelig godt skoleeksempel på datamodellering slik det bør gjøres!)
Jeg er nysgjerrig: Er det utviklet noen tilsvarende datamodell for Origo, for å strukturere ulike kilder av ulik pålitelighet, handtere indisier som er i konflikt med hverandre, spore konklusjoner tilbake til hvilke indisier de er basert på, osv? Er datamodellen offentlig tilgjengelig (på tilsvarende måte som GenTech)?
Forøvig liker jeg navnet (/uttalen) OQLT – det er ikke bare navnet i seg selv, men hvordan det i mange tilfeller beskriver realitetene!
Hei keal
Helt enig med deg i at «okkult» (OQLT) beskriver realitetene i vanskene med å finne igjen noe i arkivene. :.)
Autoriteter
De redaksjonelle prosessene er i hovedsak manuelle prosesser og har fram til nå gitt lite hjelp i å finne referansedata / masterdata / autoriteter (vi kaller det litt forskjellig i forskjellige firma). I NRK har vi som en del av Origo bygget det vi kaller Autoritetsregisteret. Dette organiserer alle data av type dataord, roller, personer, innslagstyper, kanaler, regioner (navn på NRKs distriktskontorer)kategorier, tags (beskrivende ord), stedsnavn mm.. NRK kommer til å publisere grunnlaget for en rekke av disse, så fort dette er praktisk mulig for oss. Grunnen er bl.a. at vi har eksterne samarbeidspartene som trenger tilgang til disse dataene for å levere metadata med god kvalitet (og samme referanser som vi allerede har for NRKs egne programmer).
Datamodell
NRK har utviklet datamodellen for NRK i samarbeid med den europeiske kringkastingsunionen EBU. Modellene som brukes er «technical recommendation 3293» (EBU core metadata set) og «technical recommendation 3351 (EBU class conceptual data model). NRKs metadata-arkitekter har vært meget sentrale i utviklingen av begge. Fordelen med å bruke et felles-europeisk grunnlag er at kode som er utviklet hos oss, mye enklere kan sammenstilles med arbeid som er gjort hos andre land. Og data kan utveksles mellom systemer automatisk (maskinelt) uten å måtte skrives manuelt (og på nytt).
Navn og slektsforskning
Takk for øvrig til lenker for slektsforskning som vi skal studere spesielt. Vårt arbeid med personnavn (Autoritetsregisteret) har foreløpig gjort at vi har klart å sette sammen navn fra NRKs eget lønns- og personalsystem (Agresso) med opphavspersoner fra vårt digitale musikkarkiv (DMA). I dette arbeidet har vi bl.a. klart å bruke semantiske ressurser for å koble navn. Ved hjelp av Rockipedia i Trondheim (databasen til Rockheim) har vi klart å finne ut hvem av våre egne ansatte som også er opphavspersoner til musikkverk/artister. Personsregisteret er foreløpig på over 450.000 navn. NRK arbeider nå med å gjøre dette tilgjengelig i våre egne produksjonssystemer. Det vil på sikt gi færre feil i metadata (bedre søk – både for våre egne journalister og for publikum).
GeirB
Interessant artikkel, artig å få lese mer om hvordan dere løser slike ting i NRK.
Jeg liker godt måten man kombinerer søkekriterier på i Potion. Håper på at vi som publikum også vil kunne få en slik type søkemotor mot arkivene!
Hei Karl Yngve Lervåg
Både NRK medietjenester (Origo) og NRK Medieutvikling (nrk.no / tv.nrk.no mm.) bruker samme søketeknologi (Lucene Elasticsearch). Det pågår et arbeid på å gi bedre søketeknologi og gjøre det enklere for publikum å «oppdage» programmene selv. Origo grunnlaget vil i seg selv gjøre at publikum får et bedre grunnlag å søke i, men selve søket mot publikum må bygges av Medieutvikling som en del av videreutvikling av nrk.no og tv.nrk.no / radio.nrk.no
Geir
Jeg er også veldig interessert i muligheten til å søke i historiske programoversikter. For øyeblikket bruker jeg Aftenposten og Dagbladets avisarkiv for å finne programmer som har vært sendt. Men, siden det ikke er mulig å avgrense søkene til bare radio/tv, og spesielt siden kvaliteten på OCRen som er gjort er, skal vi si, svært varierende, så er dette langt fra optimalt.
Hei Trond
Søk i gamle NRK programoversikter er et vanskelig område, som også vi ønsker oss bedre tilgang til. Du kan finne noe i oversiktene til Nasjonalbiblioket – prøv f.eks denne lenken. nb.no/nbsok/search?page=0&menuOpen=false&instant=true&action=search¤tHit=9…
NRK og NB har startet et arbeid for å digitalisere såkalte «senderapporter» – sendeplaner med sendeleders kommentarer (endringer) for både radio og TV. Disse rapportene var lagret i papir form (fra 1930-tallet) – og de er håndskrevet helt fram til 1950-tallet. Alle disse (tusenvis!) av permer blir nå digitalisert av Nasjonalbiblioteket. Vår plan er å bruke dem som grunnlag til bedre metadata – særlig for den eldste delen av Radioarkivet. I dette arbeidet er også Programbladet en mulig kilde til metadata. Programbladet, før «Hallo, hallo», dekker tidsrommet 1946-2017.
GeirB
Hei og takk for fin artikkel.
Hvordan og hvor lagrer dere alle de Petabytene ?
Høres ut som veldig mange tusen harddisker / datateiper / serverrack. Og det skal jo backes opp også.
Er datalagringen i egne lokaler eller kjøper dere tjenesten av en ekstern leverandør ?
Radioprogrammene (og TV) skal uansett lagres i Nasjonalbibliotekets arkiv i fjellhallen i Mo i Rana. Sikkerhetskopiering blir ivaretatt under ett for alt digital arkivmateriale som NB handterer. Teknologien moderniseres regelmessig: Fram til ca. 2005 var «robotiserte» DAT-maskiner det primære sikkerhets-mediet. Å hente inn en fil kunne ta et minutt eller to, men det var fullt automatisert. Rundt 2005 tok RAID-disker over (og da NB innhentet pris på disker var det pris pr palle disker som ble vurdert :-)), og det ga institusjoner som NRK langt bedre muligheter for å søke i arkivene. Jeg tror DAT-roboten ble stående for en gang imellom å ta langsiktig kopi for off-site lagring. NB og Riksarkivet har gjensidige avtaler om å lagre off-site sikkerhetskopier for hverandre.
Jeg har ikke fulgt med de siste årene, men tar nærmest for gitt at NB stadig har en STOR vegg full med RAID-disker som sitt hovedlager (men diskene er naturligvis fornyet til større kapasitet). Det er vel tvilsomt om DAT brukes for off-site lagring i dag, men jeg vet ikke hva som reelt brukes. (Det kan være klassifisert informasjon, for å redusere risikoen for sabotasjeaksjoner.)
NRK kan selvsagt hente fram enkelt-programmer til egne filtjenere, for videre behandling, reprisesending osv., men nett-kapasiteten mellom Marienlyst og fjellhallen i Mo i Rana er såpass god at det ikke er behov for å ha en komplett kopi av arkivet lengre sørpå.
Og: Ja, det finnes minst to helt uavhengige signalveier mellom arkivet og Marienlyst. Du skal grave over mer enn én fiber for å kutte NRKs tilgang til arkivet. Jeg kjenner konkret til at for noen år siden ble det avvist et forslag om å bygge en sentral «koblingstavle» ved NB for å enkelt kunne flytte over til en alternativ forbindelse ved problemer: Det ble avvist fordi det ville skape ett enkelt sårbart punkt. Et enkelt angrep mot en slik tavle kunne ramme samtlige signalveier. De ulike tilkoblingene skal gå separate traseer helt inn i fjellhallen.
Hei igjen keal
Nasjonalbibliotekets hovedlagringssystem er et Oracle StorageTek SL-series «modular Library system». Dette er samme type som NRK bruker, men de har litt mer plass enn oss (ca 10.000+ taper). NRK har alle progammer også i eget system. (Sikkerhet og bruksbehov tilsier ikke at vi henter via fiber mellom NRK og NB uten at dette er helt nødvendig.)
Når NRK hentet tilbake hele radiosamlingen (ved byggingen av nytt radioarkiv) var raskeste måte å sende ned ca 1 PB med materiale å tanke opp et gammelt serversystem – og sende dette med lastebil til NRK i Oslo. Alternativet var å belegge fiberlinjer mellom NRK og NB i ett år! Man skal ikke undervurdere datahastigheten av lastebil på E6… :.)
En ekstra sikkerhet er for øvrig at alle gamle taper fra NRK gradvis er overført til Nasjonalbibliotekets fjellhaller – inkl maskinteknologi. NRK har nå bare ca 2-3 år igjen av digitaliseringsprosessen. Selv om vi regner med at gamle taper kommer til å dukket opp i flere tiår framover – og må digitaliseres.
GeirB
Hei Ole Christian
Mengden i lagringen av NRKs programmer er knyttet til mediefilene – i internt datamodell-språk «essence». Metadataene bak programmene tar så lite plass at de faktisk i mange tilfeller kan plasseres i RAM på et server-system (såkalt «in-memory computing»).
Les mer her: gridgain.com/resources/blog/in-memory-computing-in-plain-english
In-memory teknikker gjør at vi kan øke søkehastighet med en faktor på 1000+.
Lagringen av «essence»/mediefilene er en utfordring fordi de ikke bare er å plassere disse hvor som helst. Mediefilene er bruksfiler som må plasseres i tett tilknytning til redigerings-, avviklings- og publiseringssystemer – som bruker disse. Dette gjør at vi fram til nå først og fremst ha lagret mediefilene lokalt i NRK (Oslo + distriktskontorer). I tillegg har vi backup av både metadata og mediefiler hos Nasjonalbiblioteket (NB)i Mo i Rana. Den såkalte «pliktavleveringsloven» sikrer også at alt som vi sender, blir avlevert til NB.
nb.no/Om-NB/Pliktavlevering/Hva-skal-pliktavleveres
Hovedverktøyet for lagring i NRK (og NB) er en stor taperobot fra Oracle/Sun/StorageTek med plass til ca 30 PB på 6000+ datataper (størrelse 5,5 TB). I tillegg brukes en rekke store videoservere og lagringsservere (NAS/SAN) for redigering – og for råstofflagring (Apple XSAN).
NRK har nylig gjort store investeringer i nye lagringsservere, så 16 PB med ny lagring er under installasjon i disse dager (Dell/EMC Isilon).
NRK har også under installasjon en såkalt «private cloud» for backup. Og våre publiseringsfiler (tv.nrk.no) er lagret hos firmaet Media Network (Økern, Oslo). Her ligger ca 300.000 radio og tv-programmer lagret i kvaliteter som egner seg for nettpublisering – og for distribusjon via flere CDN-er (Content Delivery Network).
NRK bruker også en rekke sky-leverandører for bl.a. nettleveranser (web-servere) og programproduksjon (redigering, råstoffleveranse, leveranse fra eksterne programprodusenter) – men bare i liten grad for arkivering. Men dette kan endre seg med bedre tilgang – og høyere hastigheter i nettilgang for NRK.
Veldig godt forklart, Geir. Likte eksemplene du brukte, spesielt det med Briksdalsbreen/Nigardsbreen. Ofte gjør hukommelsen oss et puss.
Genererer dere nye metadata ved hjelp av maskinlæring? Skulle tro at det er mulig.
Hei Olav
Vi generer ikke metadata via maskinlæring pr i dag, men arbeider med dette innad i prosjektet nå. De mest interessante områdene er autotagging (finne søkord basert på tale til tekst analyse) og persongjenfinning (basert på stemmemønster og ansiktsgjenkjenning). Mange programmer har svært dårlige metadata som vanskeliggjør gjenfinning uten at man har helt presise data fra andre kilder. Radioarkivet har f.eks over 125.000 Dagsnytt-sendinger – mange av dem rent talebasert uten innslag (bulletiner). I disse ville søkeord basert på tale til tekst kunne gjøre søkebare på tema.
Persongjenfinning ønsker vi også å linke med nytt autoritetsregister for personer (heter «agenter» internt). Dagens metadata har en ganske høy feilprosent i feilstavelser – særlig i «medvirkende» metadata i produksjonsdata for radio. TV metadata er ofte bedre kvalitetssjekket fordi de også ofte vises visuelt (supertekster).
GeirB
Er det mulig å teste?
Prøvde å gå til https://radioarkiv.nrk.no men fikk ikke opp noe.
Hei Raymond
Radioarkivet er pr i dag kun en intern NRK-tjeneste (tilgjengelig for alle NRK-medarbeidere). Men alle radioprogrammer som vi har rettigheter til ligger i Radiospilleren (inkl en del av metadataene fra Radioarkivet). http://radio.nrk.no Pr i dag er dette nesten 200.000 programmer. (Dette utgjør ca. 30% av samlingen.)
GeirB