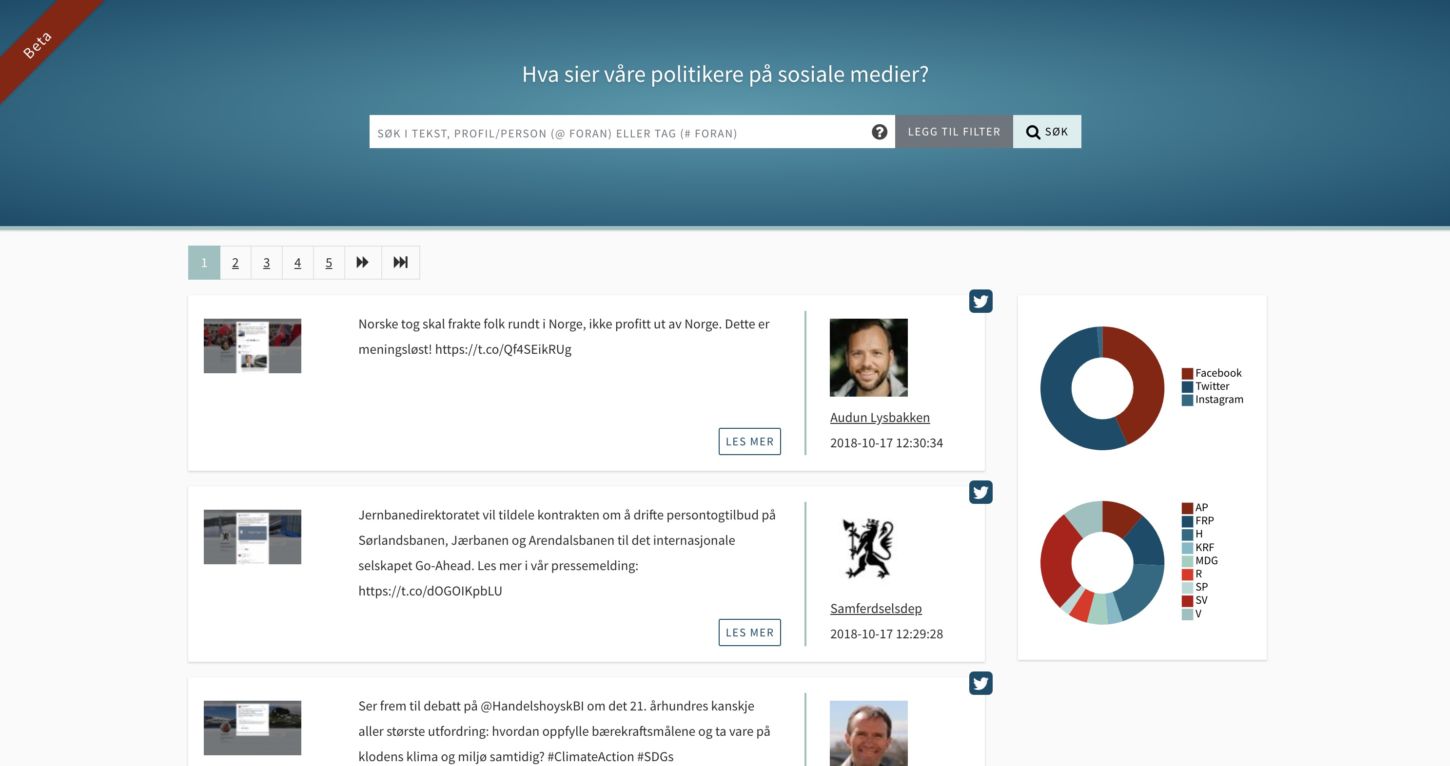
Arkivverket lagrer nå alt de folkevalgte på Stortinget publiserer på sosiale medier; selv om det blir slettet.
En viktig del av samfunnsdebatten foregår i dag på sosiale medier, men det har det vært lite koordinert innsats for å lagre hva norske politikere publiserer der. Fram til nå.
Arkivverket har jobbet i rundt et år med en ny tjeneste hvor du kan søke i innlegg på Facebook, Instagram og Twitter fra kontoer som tilhører norske politikere på stortinget, deres partier og de ulike departementene.
– Dette utgjør i dag oppunder 200 ulike kilder, skriver Espen Sjøvoll i en e-post til NRKbeta. Han er avdelingsdirektør i Arkivverket og ansvarlig for prosjektet som nylig ble lansert.
Viktige kanaler
Sjøvoll trekker fram Arkivverkets rolle som Norges «felles hukommelse», når han forklarer hvorfor de har gjort dette:
– Formålet vårt er at våre arkiver skal gi et bilde av den norske samfunnsutviklingen. Vi innså at sosiale medier både er blitt viktige kanaler for samfunnsdebatt og i hverdagen til mange enkeltmennesker, samtidig er sosiale medier flyktige, forklarer Sjøvoll.
– Mange tror at «ingenting blir glemt på internett», men det stemmer ikke.

Innlegg som slettes
– Bør grunnlaget for en viktig verdidebatt i Norge i 2018 kunne slettes med et klikk? spurte Sjøvoll i en kronikk i Klassekampen i mars, etter at Sylvi Listhaug selv slettet Facebook-innlegget som ledet til hennes avgang som justisminister.
Da hadde allerede Arkivverket jobbet en stund med å teste ut hva som skulle til for å lagre kopier av meldinger fra utvalgte personer. I sin omtale av Arkivverkets nye tjeneste, skrev Digi.no at Sylvi Listhaugs innlegg er å finne i det nye arkivet.
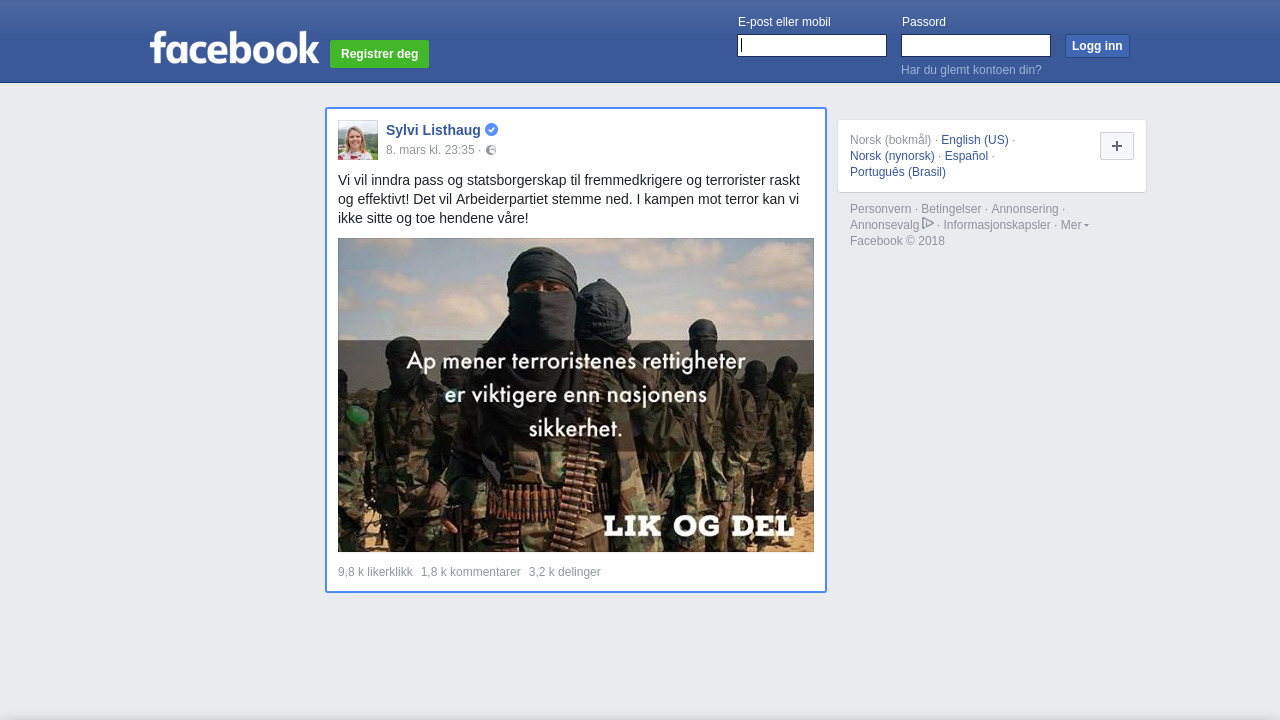
Arkivverkets mål med tjenesten er vært å ta vare på debatter også etter et sosialt medie har forsvunnet fra nettet, som blant annet norske Blink og Nettby. Vi vet fra tidligere at blant annet statsminister Erna Solbergs innlegg har blitt slettet av Facebook. Selv om Arkivverket nå lagrer det meste, får de ikke nødvendigvis med seg alt, ifølge Sjøvoll.
– Vi samler inn kopier av innlegg fortløpende, men det ligger et visst tidsintervall mellom hvert søk. Hvis innlegget slettes etter vi har tatt en kopi så forblir det lagret i vår løsning. Her kan det være ulike vurderinger for og mot, men vi beholder foreløpig kopiene, forklarer Sjøvoll.
Så langt er det SV og Fremskrittspartiet som har publisert flest innlegg siden Arkivverket startet å fylle sitt sosiale medier-arkiv. Statsminister Erna Solberg er med sine 900 innlegg på en 17. plass. Med tanke på at Solberg har publisert over 5800 tweets siden hun registrerte seg på Twitter, kan ikke dette betraktes som et fullstendig arkiv med stortingspolitikeres aktivitet på sosiale medier.
Vil ikke lagre hele internett
Arkivverket har foreløpig ikke noe samarbeid med andre arkiv-tjenester som Wayback Machine, selv om de har hatt møter og annen dialog med Internet Archive som står bak denne.
– Vi har ikke kapasitet eller interesse av å ta en kopi av internett, men er opptatt av å lagre viktig og utvalgt informasjon, forteller Sjøvoll.
Han viser til hvordan Library of Congress i USA gikk høyt på banen i 2010, og kunngjorde at de hadde skaffet seg fram til da og ville fortsette med å lagre alle offentlige Twitter-meldinger.
Her har det likevel dukket opp skjær i sjøen. Den akkkumulerte datamengden av alle Twitter-meldinger ble nemlig stor, og i desember i fjor kunngjorde Library of Congress at de kun vil hente inn utvalgte Twitter-meldinger fra nå av.
Det er en tragedie, ifølge den australske professoren Axel Bruns. Han har tidligere studert den norske «twittersfæren» inngående og omtalte i januar Library of Congress’ sin beslutning om å droppe all innsamling av tweets for «en tabbe av historiske dimensjoner».


Han mener at kun fullstendige arkiv av tjenester som Facebook og Twitter vil gjøre det mulig for forskere i framtiden å analysere de store spørsmålene i vår tid; som filterbobler, ekkokamre og hvordan falske og automatiserte kontoer kan ha påvirket valg.
Foreløpig er ikke ambisjonene til Arkivverket så store, men de ønsker å utvide tjenesten.
– Vår ambisjon er å kunne få frem samfunnsutviklingen og det skjer mye utenfor den politiske arenaen. Vi ønsker å utvide tjenesten til å samle innlegg fra også andre personer eller organisasjoner, forteller Sjøvoll.
– Det kan være bloggere, samfunnssynsere, interesseorganisasjoner, forfattere, treningseksperter eller andre vi anser som viktige å dokumentere for fremtiden.

Nøyaktig hvordan Arkivverket skal velge ut hvem som skal «bli husket» har de foreløpig ikke bestemt.
Bygger løsningen selv
Arkivverket bruker både egenutviklede verktøy og andres for å lagre informasjonen.
– Vi har en avtale med selskapet Retriever om medieovervåkning. De gjør hovedjobben med å søke gjennom de ulike tjenestene og lager en liste med innlegg fra kontoene vi har definert, forteller Sjøvoll.
Hvordan dataene struktureres i Arkivverkets egen database og presentasjonen av disse på nettet er utviklet internt.
Ulike metadata
Rent teknisk tar løsningen et skjermbilde av toppen av innlegget, slik det vises i nettutgaven av det sosiale medie. Arkivverket lagrer også følgende metadata fra de ulike innleggene:
- Lenke til posten og kilde, med tidsstempel (Lenken vil sannsynligvis slutte å virke på et tidspunkt i fremtiden)
- Tekstinnhold, evt. tittel og beskrivelse (avhengig av tjenesten)
- Bilde(r) tilknyttet innlegget
- Lenke med stillbilde til evt. video i innlegget
- Forfatter, lenke til forfatters profil, forfatters profilbilde
- «Expanded» URL – lenke videre – som Twitters «t.co» og «bit.ly» lenker
- Skjermbilder og Thumbnails (av «hodet» i posten)
Kommentarer til ulike innlegg er ikke lagret, da Arkivverket ikke har fått avklart personvernspørsmål rundt dette, skriver Sjøvoll og fortsetter:
– Vi får heller ikke laget videostrømmer, da disse er sperret for uthenting av Facebook.
Ønsker ris og ros
Tjenesten er foreløpig i beta-utgave, og Sjøvoll ønsker gjerne tilbakemeldinger.
– En viktig side med beta-publisering er å få avdekket tekniske svakheter som direkte feil i kodingen, om kapasiteten er god og slike ting, forteller Sjøvoll.
På Arkivverkets blogg skriver de at en rekke innspill vil bli adressert i framtiden – som at nettsiden skal kjøre på HTTPS og gi en mer detaljert oversikt over størrelsen på arkivet.
Du kan søke i arkivet her.
beta.some.arkivverket.no/post/18382
Denne tjenesten arkiverer innhold postet av andre på veggen til politikere, og viser det sammen med navn og bilde av politikeren som om det var politikerens egene ytring.
Om nettsiden skal virke som en troverdig kilde, må ting som dette ordnes opp i – det er lett å bruke innhold som dette sensasjonellt, uten at feilen blir plukket opp av mange.
Godt sett, Liam! Har tipset Arkivverket som skal se på saken. Fin ting å luke ut i en beta-fase.
Sweet!
Forøvrig hadde det vært fint med en lett måte for oss som brukere å rapportere problemer selv, i og med at det er en beta-tjeneste
Hei Liam,
Vi fikk denne videresendt fra Ståle og undersøker hvorfor dette skjer. Foreløpig er det ikke konsekvent at alle andres posts kommer med – litt ulikt hva som fanges fra andre og ikke – så vi undersøker.
Når det gjelder innspill til tjenesten har vi en egen side – men den er kanskje ikke så intuitiv å finne: beta.arkivverket.no/post/178756836640/s%C3%B8k-i-politikeres-innlegg-p%C3%A5-sosiale-medier#disqus_t…
Det jeg liker best med denne tjenesten er at den virker som den legger ut alt, fra begge sider? Ulikt Facebook, som prøver å bare gi deg informasjon du er enig i?
Hei,
Det er godt å høre du liker tjenesten. Vi legger ut alt og det skjer ingen filtrering eller tilpassing av innholdet til den enkelte leser.
For rundt femten år siden hadde Nasjonalbiblioteket et prosjekt for å arkivere hele «det norske internettet» regelmessig, i et samarbeidsprosjekt med nettopp Wayback Machine, nevnt i artikkelen (og andre).
Her tillot ikke ressursene at man ikke lagret alt. Datamengden var så overveldende at det var helt urealistisk å vurdere enkelt-sider, ikke engang enkelt-nettsteder, for bevaring eller kassasjon. Alt skulle bevares. Automatisk analyse ble brukt (der tekstinnhold var en relativt marginal faktor i vurderingen) for å prioritere hva som skulle foreslås for bibliotekarer for katalogisering – kall det gjerne innslag i kvalitetssikrede søkeindekser. Så kunne man starte på toppen av den prioriterte lista og katalogisere så mye som ressursene tillot; resten ville kun være tilgjengelig gjennom et «google-lignende» søk, der du for hvert treff kunne bla deg tilbake i nettsidens historie (slik du kan på Wayback Machine).
Jeg vet ikke hva det ble ut av dette prosjektet, om det noen sinne ble ferdigstilt.
Sosiale medier er på mange måter «enklere» enn nettet var for femten år siden: «Tradisjonelle» nettsider hadde utviklet seg fra statiske presentasjoner av tekst, bilder og grafikk til å bli interaktive database-portaler, enten det var baser over produkter i nettbutikken, nyhetsmeldinger eller ulike organisasjoners informasjon om sin aktivitet. Gjennom web-grensesnittet kunne man som regel bare bevare «eksempler», hvordan nettsiden så ut for ett spesielt søk. Å bevare all informasjon tilgjengelig på nett ville kreve direkte tilgang til selve databasen – men da mistet man presentasjonen. Uansett ville nettstedene bare unntaksvis gi direkte tilgang til databasen, og det ville i alle fall bare være et statisk snapshot av basen gjort med relativt lange intervaller.
De fleste sosiale medier er i langt større grad som en enkel loggbok: Nye elementer legges til på slutten, det gamle modifiseres ikke. Eventuelt kan det bli laget sidespor, av type «kommentar-kjeder», men også de er på samme måten: Alt legges til på slutten av greina, det som allede er presentert blir sjelden/aldri endret. Elementene består som regel av enkle media og strukturer: Tekst, bilder, video. Ingen publiserer noe på sosiale media som er i nærheten av produkt-databasen til Komplett.no!
Dessuten er volumet svært begreneset. Tekst og fotos, som utgjør hovedmengden av sosial informasjon, er jordnøtter i sammenligning med f.eks. geografisk informasjon. Selv video er relativt beskjedent, om vi med «sosiale media» primært regner det folk selv har produsert. (Å legge ut en hel DVD-film på YouTube er kanksje teknisk sett å regne som sosiale media, men sosialt sett noe helt annet enn tweets og status-oppdateringer på FB).
Vi burde ha viktigere ting å bruke ressurser på enn å sensurere bort tweets som ikke skal bevares, når kostnaden for å bevare dem har stykkpris mellom mikro-cents og milli-cents.
Ressursene burde heller brukes på å utvikle brukergrensesnitt for «avansert søk» som er slik at vanlige folk kan bruke dem! Selv om mekanismen «finnes», er det nærmest proforma: De er som regel elendige i søkekriterier som tilbys, hvordan interaksjonen med brukeren er, og presentasjon av resultatet. Så 99,99% av brukerne googler blindt på ord i teksten, og gir opp avansert søk etter første forsøk. For å bruke tekniske begreper: Vi ender opp med 99% fullstendighet (dvs. 99% av alt brukeren reelt er interessert har kommet med i trefflista … ett eller annet sted, blant 17,8 millioner treff), men 0,0001% presisjon (dvs. at bare ett av ti tusen presenterte treff er reelt av interesse).
Klarer vi å lage avanserte søk som er så brukervennlige, og så funksjonelle, at brukerne kan ta sjumilssteg fram mot kun relevante treff (dvs. presisjon 100%), og at alle relevante treff kommer med (dvs. 100% fullstendighet)… Hadde vi hatt noe i nærheten av det, ville det ikke vært det minste problem med å bevare alt, og tilby en slik søkemekanisme mot arkivet.
100/100 er selvsagt fullstendig urealistisk (ett problem er at mange som søker ikke vet hvilken informasjon de ønsker :-)). Men kan vi tilby noe som betydelig øker presisjonen, dvs. bedre klarer å skille bort irrelevant informasjon, da gjør vi brukerne en stor tjeneste.
I så henseende kan vi lære noe fra nettbutikkene: Noen av dem har svært gode søk der du kan stegvis zoome inn på akkurat det du er på jakt etter. Fra andre nettbutikker kan vi lære hvordan det ikke skal gjøres – de som har hoppet på google-filosofien om at «Min treffliste er lenge enn din, så da så!» – nettbutikken skjønner ikke hvor kunde-uvennlig det er.
Mange av de som lager søke-grensesnitt i dag kunne med stort utbytte plukke opp stoff om hva man forventet seg for tjue og tretti år siden, før google med «17.9 millioner treff» slo seg opp som idealet. Kanskje det idealet ikke er det som tjener brukerne best.
Hvis vi får andre ideer enn de vi har i dag (der antall siffer i «Antall treff» synes å være det altoverskyggende), stiller andre krav til søkemekanismer, kan det bli langt mer realistisk å forvente at alt blir lagret, f.eks. fra sosiale media.
… Hvis vi nå ønsker at alt på sosiale media skal bli bevart. Alle tolvåringer vet at de har sittet på potte, men ikke alle tolvåringer setter pris på at det er bevart fotografiske minner om det på FB for all ettertid.
Er det mulig å få et nøyaktig antall treff på et søk?
Vanskelig å føre statistikk på «Over 1000 treff»